Seize the Day
《剑与勇士(Swords & Soldiers)》的游戏AI设计
前言
偶然发现收藏夹里躺了多年的文章链接1,写作时间是2011年前后,作者是 Ronimo Games 的联合创始人 Joost van Dongen,简述了当时他们如何构建《剑与勇士》的 AI。《剑与勇士》(Swords & Soldiers)是 Ronimo Games 在2009年开发的一款2D横向卷轴RTS游戏。
简单翻译整理了一下,看看有没有参考价值。
译文
众所周知,为策略游戏创建良好的 AI 是一项艰巨的任务。AI 设计当然从来都不是一件容易的事,但对于策略游戏来说,选项和情况的复杂性非常高。我认为《剑与勇士》是第一款在游戏中实现真正出色 AI 的游戏,所以我想看看我们是如何做到这一点的会很有趣。

人工智能领域要么解决非常简单的问题,比如国际象棋(与实时战略游戏相比,国际象棋非常简单,更不用说与现实世界相比了!),要么只会提供大量精巧高效的辅助算法,比如寻路。在复杂情况下做出真正的决策本质上是一个尚未解决的问题,而且不会在短期内得到解决。
…《巨兽战争(Gigantic)》的游戏AI行为树设计
偶然看到 Managing AI in Gigantic 和 Advanced Behavior Tree Structures 这两篇文章,简述了一款 PvPvE 游戏 Gigantic 的 AI 架构,提供了一些不一样的思路。
背景

Gigantic是一个结合了PVE的5v5的多人对战游戏。对战双方各有一个叫做守护者的NPC巨兽。玩家通过在己方泉水召唤生物,定时收集泉水,通过击杀敌方英雄或泉水召唤物来为己方巨兽充能。双方围绕保护己方巨兽,攻击敌方巨兽来展开对抗,直到消灭对方巨兽,赢得胜利。
作为一款快节奏的PvPvE游戏,NPC守护者是游戏的关键要素,其AI的表现至关重要。
有限状态机不够灵活,重用节点不方便。使用行为树可以解决这一问题,而且可以轻松地同 Utility AI,GOAP 等其它方案结合。
…了解敌人:《光环战争2》的AI设计

前言
Title: Know Your Enemy: Getting to Know the AI Behind Halo Wars 2
Reporter: Drerek Fagan
Conference: Game AI North, 2017
在《Know Your Enemy: Getting to Know the AI Behind Halo Wars 2》1 这次演讲中,Drerek Fagan 介绍了《光环战争2》指挥官 AI 的工作原理,以及整个 AI 系统从战术层面到战略层面的设计和实现。
Derek Fagan 是 Creative Assembly 公司《全面战争》游戏团队中的一名 AI 程序员。2015年,他加入该公司开发了《光环战争2》的指挥官 AI 系统,从此开启了自己游戏开发的职业生涯。Derek 对人工智能的主要兴趣领域是 NPC 行为和机器学习。他于2016年从都柏林圣三一学院获得了计算机科学博士学位,论文研究主题是多智能体强化学习。
…《光环3》行为树AI的进化

这是2007年游戏开发者大会(GDC ‘07)上的一篇演讲,Bungie Studios 的 Max Dyckhoff 介绍了从《光环2》到《光环3》,开发团队对其行为树 AI 系统所做的改进。
Stimulus Behaviors
问题: 在行为树每次更新时,很少触发的事件驱动行为也会检查。在一定程度上引起了不必要的性能消耗。
Halo 2: 将行为或冲动以动态或异步的方式添加到行为树的指定位置。
…《光环 2》的游戏AI系统设计
Conference: GDC 2005
Speaker(s) : Damian Isla
Video: Managing Complexity in the Halo 2 AI System - YouTube
《光环》系列的 AI 久负盛名,其行为树的应用堪称业界典范。而 Damian Isla 在 GDC 2005 的演讲《Managing Complexity in the Halo 2 AI System》成了行为树架构设计绕不开的参考资料。结合演讲视频和演示幻灯片,精读了文章《GDC 2005 Proceeding: Handling Complexity in the Halo 2 AI》。
复杂性问题
可扩展性的复杂性
可扩展性(Scalability)的3个维度:
- Variety: 大量不同的角色:野猪兽,精英,鬼面兽,猎人,地狱伞兵,海军陆战队……
- Variation: 不同的使用故事场景:叙事性,节奏性,戏剧性,挑战性……
- Volume: 大量不同的行为:近战,射击,驾驶,躲藏……
设计需求的复杂性
- Transparency:即使是不了解 AI 内部工作原理的外行观察者(玩家)能够对AI的内部状态做出合理的推断,并以此来解释和预测AI的行为。
- Coherence:保持行为的连贯性和一致性。为了让AI的行为更连贯自然,需要注意启动、停止动作的时机合理。还要特别防止 AI 行为中出现摇摆不定问题,即在两个选项间反复切换的现象。
- Directability:保证可指挥性,AI 系统应该能够接受设计师的指示和命令。
- Workability:对设计和开发它的工程师应该要有足够的可操作性,工程师需要能够读取、理解AI系统内部的状态和运作机制,对 AI 系统进行测试、调试、修改与优化。
如何管理复杂性
决策机制
行为 DAG
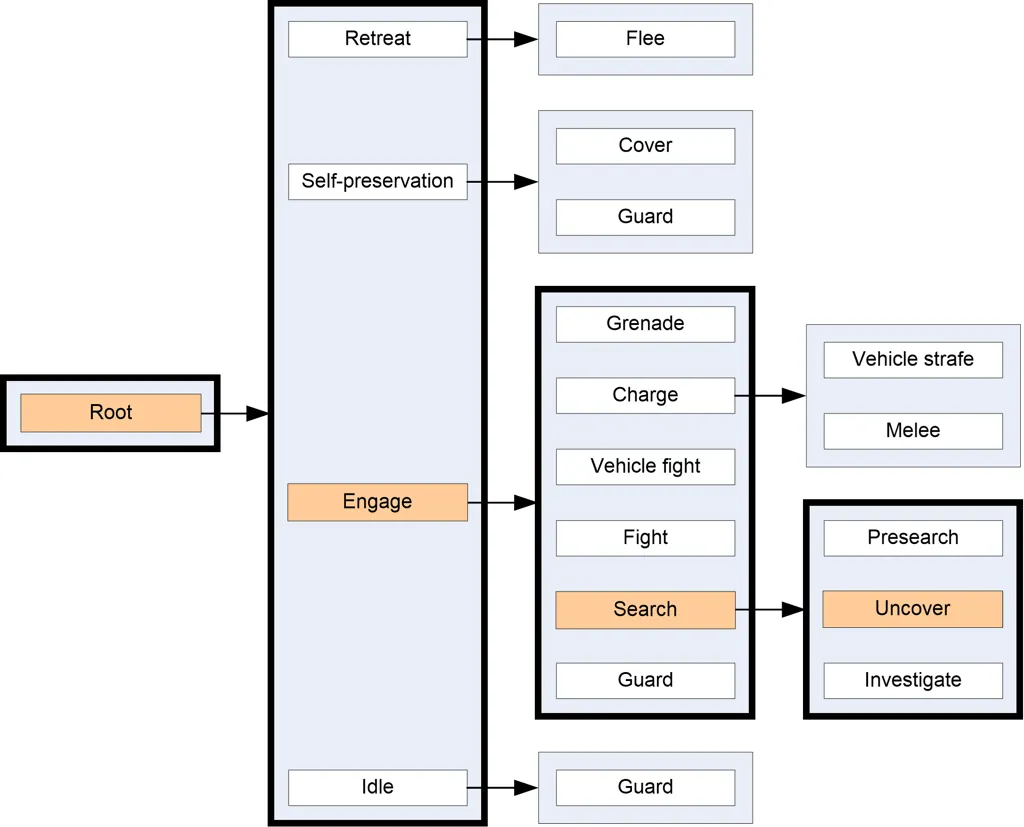
Halo 2 AI实现了行为树,更具体地说,是行为DAG(有向无环图),因为单个行为(或行为子树)可以占据图中的多个位置。下图为Halo 2的实际核心行为DAG的精简版本,原图包含50种不同的行为。
游戏AI入门指南(Part 3)
学习能力和适应能力
我们在一开始就提到游戏AI通常不使用“机器学习”,因为它不适合游戏世界中智能代理的实时控制。但这并不意味着我们不能从机器学习领域中汲取灵感。也许我们希望射击游戏中的AI对手去学习寻找最佳位置,以便获得最多的击杀数。或者在像《铁拳》或《街头霸王》这样的格斗游戏中,当我们使用一遍又一遍地使用相同的“组合技”时,AI对手能学会应对从而迫使我们使用其它的战术。因此有时候一定程度的机器学习还是很有用处的。
统计和概率
在我们研究更复杂的例子之前,值得考虑一下:通过使用一些简单测量得出的数据来做出决策,我们可以走多远?例如,假设有一个即时战略游戏(Real-time strategy game),我们要猜测玩家是否会在前几分钟内发起一次快攻,以此来决定是否需要加强防御。也许我们可以从玩家的过去行为中推断出未来的行为。一开始我们没有可以推断的玩家数据,但每次AI与人类对手对战时,它都可以记录第一次攻击的时间。经过多次对战,这些时间的平均值可以非常近似于将来该玩家攻击的时间。
但简单地平均化存在一个的问题:它会随着时间的推移而趋向于居中。因此如果玩家在前20次采用快攻策略,而在接下来的20次采用较慢的策略,那么平均数将处于中间位置,这个数值对我们来说一点用处也没有。纠正此问题的一种方法是简单的移动平均(windowed average),如只考虑最后20个数据点。
假设玩家过去的偏好会延续到将来,在估计某些动作发生的可能性时可以使用类似的方法。例如,如果玩家用火球术攻击5次,闪电箭攻击2次,又进行了1次近战攻击,那么他很可能喜欢火球术,每8次使用5次。由此推论,我们可以得出使用不同攻击的概率为:火球术= 62.5%,闪电箭= 25%,近战= 12.5%。建议我们的AI角色找一些抗火装备!
另一个有趣的方法是使用朴素贝叶斯分类器(Naive Bayes Classifier)来检查大量输入数据并对当前情况进行分类,以便AI代理可以适当地做出反应。贝叶斯分类器最著名的应用就是电子邮件垃圾邮件过滤,它会检查电子邮件中的单词,比较这些单词在之前主要出现在垃圾邮件还是非垃圾邮件中,以此来判断新邮件是不是垃圾邮件。我们也可以做类似的事情,只是我们的输入数据有点少。通过记录所有我们了解到的有用信息(如建造了哪些敌方单位,使用了哪些法术,研究了哪些科技),然后记录由此产生的结果(战争还是和平,速攻策略还是防御策略等),根据这些我们可以选择适当的行为。
使用所有这些学习方法,足够(通常更可取的是)在发售之前进行游戏测试期间对收集的数据进行处理。让AI可以应对游戏测试者的不同策略,但在游戏发售后不会改变。相比之下,发售后能够应对玩家的AI可能最终会变得过于可预测而呆板乏味,或者太难而以击败。
…