游戏AI入门指南(Part 3)
学习能力和适应能力
我们在一开始就提到游戏AI通常不使用“机器学习”,因为它不适合游戏世界中智能代理的实时控制。但这并不意味着我们不能从机器学习领域中汲取灵感。也许我们希望射击游戏中的AI对手去学习寻找最佳位置,以便获得最多的击杀数。或者在像《铁拳》或《街头霸王》这样的格斗游戏中,当我们使用一遍又一遍地使用相同的“组合技”时,AI对手能学会应对从而迫使我们使用其它的战术。因此有时候一定程度的机器学习还是很有用处的。
统计和概率
在我们研究更复杂的例子之前,值得考虑一下:通过使用一些简单测量得出的数据来做出决策,我们可以走多远?例如,假设有一个即时战略游戏(Real-time strategy game),我们要猜测玩家是否会在前几分钟内发起一次快攻,以此来决定是否需要加强防御。也许我们可以从玩家的过去行为中推断出未来的行为。一开始我们没有可以推断的玩家数据,但每次AI与人类对手对战时,它都可以记录第一次攻击的时间。经过多次对战,这些时间的平均值可以非常近似于将来该玩家攻击的时间。
但简单地平均化存在一个的问题:它会随着时间的推移而趋向于居中。因此如果玩家在前20次采用快攻策略,而在接下来的20次采用较慢的策略,那么平均数将处于中间位置,这个数值对我们来说一点用处也没有。纠正此问题的一种方法是简单的移动平均(windowed average),如只考虑最后20个数据点。
假设玩家过去的偏好会延续到将来,在估计某些动作发生的可能性时可以使用类似的方法。例如,如果玩家用火球术攻击5次,闪电箭攻击2次,又进行了1次近战攻击,那么他很可能喜欢火球术,每8次使用5次。由此推论,我们可以得出使用不同攻击的概率为:火球术= 62.5%,闪电箭= 25%,近战= 12.5%。建议我们的AI角色找一些抗火装备!
另一个有趣的方法是使用朴素贝叶斯分类器(Naive Bayes Classifier)来检查大量输入数据并对当前情况进行分类,以便AI代理可以适当地做出反应。贝叶斯分类器最著名的应用就是电子邮件垃圾邮件过滤,它会检查电子邮件中的单词,比较这些单词在之前主要出现在垃圾邮件还是非垃圾邮件中,以此来判断新邮件是不是垃圾邮件。我们也可以做类似的事情,只是我们的输入数据有点少。通过记录所有我们了解到的有用信息(如建造了哪些敌方单位,使用了哪些法术,研究了哪些科技),然后记录由此产生的结果(战争还是和平,速攻策略还是防御策略等),根据这些我们可以选择适当的行为。
使用所有这些学习方法,足够(通常更可取的是)在发售之前进行游戏测试期间对收集的数据进行处理。让AI可以应对游戏测试者的不同策略,但在游戏发售后不会改变。相比之下,发售后能够应对玩家的AI可能最终会变得过于可预测而呆板乏味,或者太难而以击败。
简单的基于权重的自适应
让我们更进一步讨论这个话题。不只是利用输入数据在不同的预编程策略之间选择,或许我们还想修改一系列影响决策的数值。充分了解我们的游戏世界和规则后,我们可以执行以下操作:
- 让AI在游戏过程中收集有关世界状态和关键事件的数据(如上所述);
- 以收集的数据为基础,更改其中的值或其“权重”;
- 根据处理或评估这些权重来进行决策。
假设在一张FPS游戏地图上,AI代理有几个主要房间可供选择。每个房间都有一个权重,用来表示其进入该房间的意愿,并且一开始所有房间的权重都是相等的。当代理选择要去的地方时,先随机选择一个房间,但会基于权重而有所偏向。现在设想一下,当AI代理被杀死时,它会记下其所在的房间并减轻权重,因此它以后不太可能再回到这个房间。类似地,假如AI代理因为击杀敌人得分了,那么它可能会增加其所在房间的权重,从而将其优先级提高。如果开始的时候一个房间对AI特别致命,AI代理会在将来避开这里,但如果AI代理在其他房间击杀了很多敌人,那么它会回到那里。
马尔可夫模型
如果我们想使用这样收集的数据进行预测,那该如何呢?例如玩家在玩游戏的过程中,我们记录下他们在一段时间内进入的每个房间,自然会期望用这些数据来预测玩家可能前往的下一个房间。通过跟踪玩家当前所在的房间和之前去过的房间,并将其记录为一对值,我们可以计算出前一种情况导致后一种情况的频率,并将其用于预测未来的情况。
假设有3个房间,红色,绿色和蓝色,以下是我们在游戏中的观察结果:
| 首个房间 | 总次数 | 下个房间 | 次数 | 百分比 |
|---|---|---|---|---|
| 红色 | 10 | 红色 | 2 | 20% |
| 10 | 绿色 | 7 | 70% | |
| 10 | 蓝色 | 1 | 10% | |
| 绿色 | 10 | 红色 | 3 | 30% |
| 10 | 绿色 | 5 | 50% | |
| 10 | 蓝色 | 2 | 20% | |
| 蓝色 | 8 | 红色 | 6 | 75% |
| 8 | 绿色 | 2 | 25% | |
| 8 | 蓝色 | 0 | 0% |
每个房间的观测数据相当均匀,没法告诉我们哪里最适合打埋伏。玩家在地图上的均匀分布对数据产生了影响,在这三个房间中出现有同样的可能性。但是他们进入的下个房间的数据是有用处的,可以帮我们预测玩家在地图上的移动。
我们一眼就可以看出,绿色房间显然是玩家所青睐的,大多数在红色房间的人随后都进入了绿色房间。下次检查时,绿色房间中有50%的玩家仍在呆在那里。我们还可以看出,蓝色房间是一个非常不受欢迎的地方,大家很少从红色或绿色房间转到蓝色房间,并且几乎没人会在蓝色房间中逗留。
但是数据告诉我们一些更具体的信息:它说明当玩家在蓝色房间时,他们前往的下个房间最有可能是红色房间,而不是绿色房间。尽管绿色房间总体上比红色房间更受欢迎,但如果玩家此时在蓝色房间,则这种趋势会略有逆转。下个状态(即他们选择前往的房间)显然取决于先前的状态(即他们当前所处的房间),因此与单独计算观察数据相比,这组数据能够让我们更好地预测玩家的行为。
我们利用过去状态的知识来预测未来状态的这个想法称为马尔可夫模型(Markov model) 。像示例这样具有准确可观测事件(如“玩家所在的房间”)的过程称为马尔可夫链(Markov chain)。由于它表示连续状态之间发生变化的概率,因此常用图形将其描述为有限状态机,并在相应的转换旁边标注概率。之前我们用状态机来表示代理所处的某种行为状态,但是这个概念可以扩展到任何状态,无论是否与代理相关。在这种情况下,状态则代表代理目前占据的房间,看起来像这样:
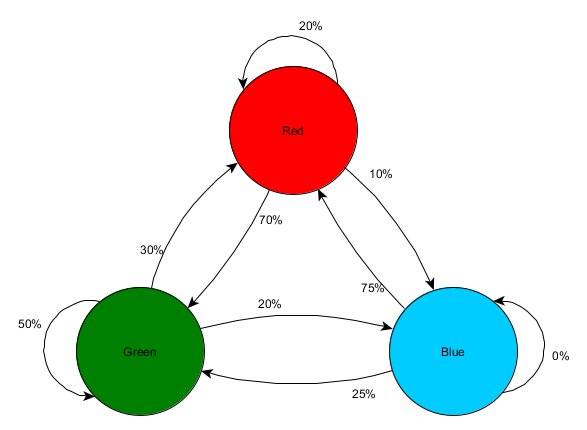
这个简单方法可以表示各个状态转换的相对概率,让AI具备了预测下个状态的能力。但是我们可以走得更远,只需通过系统来向前推演2步或更多步。
如果看到玩家在绿色房间,我们通过数据预计,下次观测时玩家仍有50%的概率呆在绿色房间。但下下次观测时他们还在那里概率是多少?这不仅包括两次观测时都在绿色房间的概率(50%* 50%= 25%),还包括玩家离开再回来的概率。下图是新的表格,将先前的数据应用到3次观测——1次当前结果和2次未来的假设结果。
| 观测 第1次 | 假设观测 第2次 | 概率 | 假设观测 第3次 | 概率 | 累积概率 |
|---|---|---|---|---|---|
| 绿色 | 红色 | 30% | 红色 | 20% | 6% |
| 绿色 | 70% | 21% | |||
| 蓝色 | 10% | 3% | |||
| 绿色 | 50% | 红色 | 30% | 15% | |
| 绿色 | 50% | 25% | |||
| 蓝色 | 20% | 10% | |||
| 蓝色 | 20% | 红色 | 75% | 15% | |
| 绿色 | 25% | 5% | |||
| 蓝色 | 0% | 0% | |||
| 总计 | 100% |
可以看出,2次观测后玩家仍然在绿色房间的概率是51%——其中21%是从红色房间过来的概率,5%是从蓝色房间过来的概率,而25%则是一直呆在绿色房间的概率。
这张表只是视觉辅助之用,计算过程只需要将每一步的概率相乘。这意味着你向前推演很多步,但有一个重要的警告:我们在假设玩家进入房间的概率完全取决于他们当前所在的房间。这就是所谓的“马尔可夫性质(Markov Property)”——未来状态仅依赖于当前状态。虽然它能够让我们使用诸如马尔可夫链之类的强大工具,但通常只是一个近似值。玩家可能会因为其他因素(如生命值或弹药量)而更换房间。由于没有采集这些信息作为状态的一部分,我们的预测将因此变得没那么准确。
N-Grams
还记得格斗游戏侦测组合技的例子吗?这里有一个类似的情况:我们希望根据过去的状态来预测未来的状态(以便决定如何格挡或躲避攻击),但我们不想检查单个状态或事件,而是要查找构成组合技的事件序列。
有一种方法是将每次输入(如Kick,Punch或Block)存储在缓冲区中,将整个缓冲区记录为事件。假设玩家反复按下Kick,Kick和Punch来使用“SuperDeathFist”攻击,那么AI系统会将所有输入存储在缓冲区中,并记住在每个步骤中使用的最后3个输入。
| 输入 | 目前输入序列 | 输入缓存 |
|---|---|---|
| Kick | Kick | none |
| Punch | Kick, Punch | none |
| Kick | Kick, Punch, Kick | Kick, Punch, Kick |
| Kick | Kick, Punch, Kick, Kick | Kick, Punch, Kick |
| Punch | Kick, Punch, Kick, Kick, Punch | Kick, Kick, Punch |
| Block | Kick, Punch, Kick, Kick, Punch, Block | Kick, Punch, Block |
| Kick | Kick, Punch, Kick, Kick, Punch, Block, Kick | Punch, Block, Kick |
| Kick | Kick, Punch, Kick, Kick, Punch, Block, Kick, Kick | Block, Kick, Kick |
| Punch | Kick, Punch, Kick, Kick, Punch, Block, Kick, Kick, Punch | Kick, Kick, Punch |
(加粗行表示玩家发起了“SuperDeathFist”攻击。)
我们来看玩家之前的输入,每次 Kick 接着另一个 Kick 之后,可以发现下一个输入始终为 Punch。这使AI代理可以做出以下预测:如果玩家刚刚选择了Kick,然后又选择了Kick,那么他们很可能接下来会选择Punch,从而触发SuperDeathFist。这使AI可以考虑选择一个反制的动作,比如格挡动作或躲避动作。
这些事件序列称为N元语法(N-gram),其中N是存储的项目数。前面的例子是一个三元语法(3-gram)(也称为"trigram"),这意味着前2个条目用于预测第3个条目。5元语法里前4个条目可以预测第5个,依此类推。
开发者需要仔细选择N元语法的大小(有时称为“顺序(order)”)。N越小所需内存也越小,由于可能的排列较少,存储的历史记录较少,因此会丢失上下文。例如一个二元语法(2-gram)(有时称为“bigram”)具有Kick,Kick条目和Kick,Punch条目,但因为无法存储Kick,Kick和Punch,所以不会意识到这样的组合技。
另一方面,较高的N值需要更多的内存,并且可能更难训练,因为会有更多可能的排列,可能你永远看不到两次相同的数字。例如,如果有Kick,Punch或Block的3种输入,那么使用10-gram 会有近60,000种不同的排列。
二元语法(bigram)模型基本上是简单的马尔可夫链,每一对“过去状态/当前状态”都是一个二元语法,你可以根据第一个状态预测第二个状态。也可以将三元语法和较大的N元语法视为马尔可夫链,除N元语法中的最后一项以外的其他所有项共同构成第一状态,最后一项是第二状态。我们的格斗游戏示例表示了从先Kick后Kick状态转变为先Kick后Punch状态的概率。通过将输入历史记录的多个条目视为一个单元,实际上我们将输入序列转换为一个状态,这为我们提供了马尔可夫性质,允许我们使用马尔可夫链来预测下一个输入,从而猜测下一步会是什么组合技。
知识表示
我们已经讨论了决策,规划以及预测的几种方法,所有这些都是基于代理对世界状态的观测。但我们如何有效地观察整个游戏世界呢?前面我们看到,表示世界地理的方式会对我们的导航方式产生巨大影响,不难想象,游戏AI的其他方面同样如此。我们怎样以高效(以便经常更新并由许多代理使用)又实用(以便我们的决策易于使用这些信息)的方式收集组织我们所需的信息?我们如何将单纯的数据转化为信息或知识?不同的游戏有不同的方法,但有一些通用的方法目前被广泛使用。
标签
有时候我们已经拥有了大量的可用数据,而我们需要的只是一种对数据进行分类和搜索的好方法。例如,游戏世界中可能有很多物体,其中一些物体可以很好地当作躲避射击的掩体。或者我们有一堆配音台词,仅在某些情况下才适用,我们想要一种方法可以快速知道哪个是哪个。有一个显而易见的办法是附加一些可以在搜索中使用的额外信息,这些信息称为标签(tags)。
以掩体为例,一个游戏世界可能有大量的道具:箱子,木桶,草丛,铁丝网。其中一些适合用作掩体,比如箱子和木桶,有些则不适合,如草和铁丝网。因此当代理执行“移动到掩体”动作时,它需要搜索局部区域中的物体来确定哪些是可用的。通常不能只按名称进行搜索,可能你有 “Crate_01”,“Crate_02” …… “Crate_27” 代表美术设计师制作的各种箱子,但你不会想在代码里搜索这些名称的。谁希望每次美术设计师制作新箱子或各种桶的时候,都要在代码中添加新的名称呢!相反,你可能会考虑搜索包含“Crate”一词的任何名称,直到有一天,美术设计师增加了一个“Broken_Crate”,虽然是个桶,但是一个有大洞不适合做掩体的桶。
所以呢,你需要创建一个“COVER”标签,并要求艺术家(美术)或设计师(策划)将该标签附加到适合作为掩体的物件上。一旦他们标记里所有的桶和(完好的)箱子,你的AI只要搜索带有该标签的物件,就可以知道它能不能作为掩体了。如果以后物件被重命名,标记依然起到作用,并且可以将其添加到以后的物件上,无需任何代码更改。
在代码里,标签通常用字符串表示,但如果你知道用到的所有标签,则可以将字符串转换为唯一的数字以节省空间并加快搜索速度。一些引擎提供内置的标签功能,例如Unity 和Unreal Engine 4,而你要做的,就是确定一组标签并在必要时使用它们。
智能对象
标签是一种将额外信息置入代理的环境,帮助其了解可用选项的方法,以便诸如“查找附近有掩护的每个地方”或者“查找周围每个敌方施法者”之类的查询可以高效执行,并以最小的工作量处理将来的游戏资源。但有时标签因为没有包含足够的信息而无法满足我们的需求。
假设在一个中世纪的城市模拟器里,冒险者会根据自己的意愿四处游荡,训练,战斗和休息。我们可以在城市周围放置训练场,并打上“TRAINING”标签,这样冒险者就可以轻松找到在哪里训练。但让我们想象一个是射箭场,另一个是巫师学校。我们想在每种情况下展示不同的动画,因为它们在“训练”标签下代表了截然不同的活动,并不是每个冒险者都会对两者都感兴趣。或许我们在一番思索后增加了“ARCHERY-TRAINING”和“MAGIC-TRAINING”两个标签,设置各自单独的训练例程,并内置不同的动画。这样确实是可行的。但假如设计团队说:“让我们来搞一个教射箭和剑术的罗宾汉学校吧!” 现在增加了剑术,然后他们又要加一个“甘道夫的法术与剑术学院”……你会发现自己需要在每个位置支持多个标签,还要根据冒险者需要进行哪方面的训练来查找不同的动画等等。
另一种方法则是将这些信息及其对玩家的影响直接存储在对象中,它可以简单地告诉AI选项是什么,然后根据代理的需要从中进行选择。然后它可以移动到相关位置,执行对象指定的相关动画(或任何其他先决条件活动),并相应地获得奖励。
| 执行动画 | 用户结果 | |
|---|---|---|
| 射箭场 | Shoot-Arrow | +10 箭术技能 |
| 魔法学校 | Sword-Duel | +10 剑术技能 |
| 罗宾汉学校 | Shoot-Arrow | +10 箭术技能 |
| Sword-Duel | +8 剑术技能 | |
| 甘道夫学院 | Sword-Duel | +5 剑术技能 |
| Cast-Spell | +10 法术技能 |
在上述4个位置附近的弓箭手角色将获得这6个选项,其中4个无关紧要,因为该角色既不是剑客也不是魔法师。通过匹配结果(本示例中为提高相应技能)而不是名字或标签,我们可以轻松地通过新行为扩展我们的世界。我们可以添加客栈为休息和食物。我们也可以允许冒险者去图书馆学习法术以及高级射箭技巧。
| 对象名称 | 执行动画 | 最终结果 |
|---|---|---|
| 旅馆 | 购买 | -10 饥饿 |
| 旅馆 | 睡觉 | -50 疲劳 |
| 图书馆 | 看书 | +10 施法技能 |
| 图书馆 | 看书 | +5 箭术技能 |
如果我们只是进行“射箭训练”行为,即使我们将“图书馆”标记为射箭训练位置,我们仍需要使用“看书”动画而不是通常的“击剑动画”处理特殊情况。通过将这些关联用数据描述并存储在世界中,智能对象系统为我们提供了更大的灵活性。
通过让对象或位置(例如图书馆,旅馆或训练学校)告诉我们其提供的服务以及角色必须做什么,我们可以使用少量的动画和简单的结果描述,从而使大量有趣的行为成为可能。不同于被动等待查询的对象,这些智能对象可以给出很多有关它们的用途以及如何使用的信息。
响应曲线
你可能经常会遇到这样一种情况,世界状态的一部分可以作为连续值来衡量,例如:
- “健康百分比”通常在0(无效)到100(完全健康)的范围内
- “最近敌人的距离”的范围从0到任意正值
你可能还会要求AI系统的某些方面需要某个范围内的连续值输入。例如,效用系统在决定是否逃跑时要考虑“到最近的敌人的距离”又要考虑“角色的当前健康状况”。
但是,系统不能仅将两个世界状态值相加来生成一个所谓的“安全”级别,因为这两个单位不具备可比性。它会认为一个距离敌人200单位远的濒死角色,和一个距离敌人100单位远的完全健康的角色一样安全!同样尽管健康百分比值大致呈线性,但距离并不是,距离200m和190m的敌人之间的差异远不如距离10m和近在迟尺敌人的差异大。
理想情况下,我们需要一种方法来执行这两种测量并将其转换为相似的范围,以便可以直接进行比较。我们希望设计师能够自由选择转换方式,以便他们可以控制每个值的相对重要性。响应曲线正是这样的工具。
对响应曲线的最简单的解释是,它是一个沿X轴输入的任意值(如“到最近的敌人的距离”)并沿Y轴输出的图形,通常为0.0到1.0的归一化值。图形中的直线或曲线确定了从输入到规范化输出的映射,设计人员调整了这些直线以获得所需的行为。
以前面的计算“安全”级别为例,我们决定将健康百分比保持为线性值,即无论是重伤还是轻伤,生命值提高10%都是一样好,因此将其映射到0到1的范围很简单:
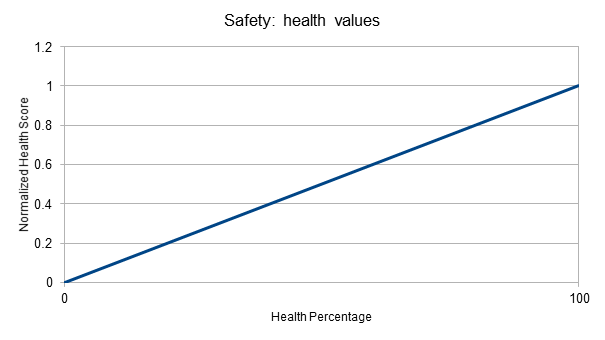
“与最近敌人的距离”略有不同,我们根本不在乎某个距离(例如50米)以外的敌人,而且我们更关心近距离而不是远距离的差异。
在这里,我们可以看到40或50米处的敌人的“安全”输出非常相似:0.96 和 1.0。
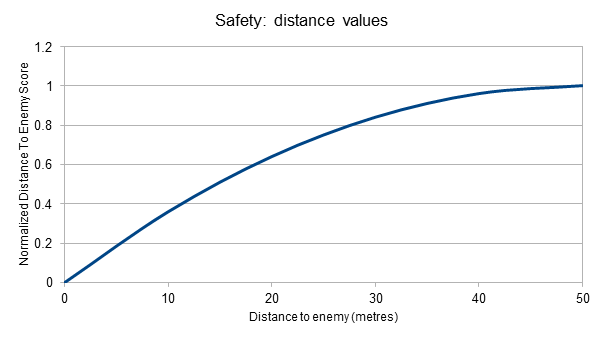
但是距离15米(y≈0.5)的敌人和距离5米(y≈0.2)的敌人之间存在更大的差别。这更好地反映了敌人靠近时的紧迫性。
通过将这两个值都缩放到0到1范围内,我们可以将总体安全值计算为两个输入值的平均值。一个拥有20%生命值且敌人在50米外的角色安全得分为0.6。一个拥有75%生命值且距离敌人仅5米的角色,安全得分为0.47。一个拥有10%生命值的重伤角色且距离敌人只有5米,其安全得分仅为0.145。
请记住以下几点:
- 通常使用某种加权平均值将响应曲线的输出合并为最终值,通过在每种情况下使用不同的权重来反映不同的重要性,可以更轻松地重用相同的曲线来计算不同的值。
- 当输入值超出规定范围时(例如上面的示例中,敌人在50米外),通常将输入值限制为最大值,以便进行计算就好像它们在该范围内一样。
- 响应曲线的实现通常采用数学方程式的形式,通常通过线性方程式或简单多项式来处理(可能限制在区间内(clamped)的)输入。但是任何一种允许设计师创建和评估曲线的系统都可以满足要求。例如,Unity AnimationCurve对象可以放置任意值,选择是否平滑处理数值之间的直线,以及评估线条上的任意值。
黑板
我们经常会遇到这样的情况:AI需要跟踪游戏过程中收集到的知识和信息,以便用于将来的决策。也许代理要记住最后攻击的角色,以便它知道短期内这个角色应该成为攻击的重点。或者它可能想记下自发现骚乱之后过了多久,因为经过一段时间后,它会停止调查并返回之前的动作。一般来说,写入数据的系统与读取数据的系统是完全分开的,因此需要从代理轻松访问它,而不是直接内置到各种AI系统中。读取可能会在写入后的某个时刻发生,需要将其存储在某个位置,以便以后可以检索(而不是按需计算,这么做不太可能)。
在硬编码的AI系统中,解决办法通常只是在需要时添加必要的变量。这些变量可以直接内联或以单独的结构或类的形式放入角色或代理的实例中,以此来保存信息。同时AI也可以根据需要读取和写入数据。这是一种效果显著的简单方法,但随着需要添加的信息越来越多,这个方法逐渐变得笨拙,而且每次都要重新编译生成游戏。
更高级的方法则是将存储数据改为允许系统读取和写入任意数据,添加新变量不通过更改代码中数据结构,更多是通过更改数据文件和脚本而无需编译构建。如果只要每个代理有一个键/值对列表(每个知识对应一个),那么各种AI系统可以协作以添加信息并在必要时读取。
这些方法在AI中被称为“黑板(blackboard)”,因为这样的想法是:每个参与者(在我们的案例中,是各种AI例程,例如感知,寻路和决策制定)都可以在需要记录时把自己知道的东西全部写在黑板上,并且可以阅读他人为完成任务而在黑板上写的其他内容。与此类似的是:一组专家聚在黑板周围,每当他们有一些有用的东西要与团队分享时,都要在黑板上写下,阅读同僚以前书写的内容,直到达成一致的解决方案或计划为止。硬编码的共享变量列表有时被称为“静态黑板”(因为存储信息的位置在运行时是固定的),相较而言,任意键/值对的列表通常被称为“动态黑板”。但作为AI系统各部分之间的信息中介,它们的使用方式几乎一样。
在传统的AI中,通常重点是众多系统之间的协作来共同解决问题。但是在游戏AI中,起作用的系统相对较少。尽管如此,仍会进行一定程度的协作。设想一个动作RPG有这些内容:
- “感知”系统会定期扫描区域,并将以下内容记录到代理的黑板上:
- “最近的敌人”:“地精#412”
- “最近的敌人距离”:35.0
- “最近的友军”:“战士#43”
- “最近的友军距离”:55.4
- “最近一次发现骚乱的时间”:下午12:45
- 诸如战斗系统之类的系统可以在发生关键事件时在黑板上记录数据,例如:
- “最近一次受伤时间”:下午12:34
许多数据可能看起来是多余的。毕竟只要知道敌人是谁并查询他们的位置,就可以轻松地随时得到最近敌人的距离。但如果为了确定代理是否受到威胁而在一帧内执行多次,这可能是一个缓慢的操作。尤其是还要重复进行空间查询,找出最近的敌人。况且也无法立即得到“最后见到的骚动”或“最后一次受伤”的时间戳,因为我们需要记录这些事情发生的时间,而黑板是存放它的合理位置。
虚幻引擎4使用动态黑板系统给它的行为树提供数据。通过提供共享的数据对象,游戏设计师可以轻松地根据他们的蓝图(可视脚本)将新值写入黑板,并且行为树以后可以读取这些值来帮助选择行为,无需重新编译引擎。
影响图(Influence Maps)
游戏AI中一个常见的问题是:确定代理应该移动到哪里?在一个射击游戏里,我们可能选择了“移动到掩体”之类的动作,但是面对移动的敌人,我们如何确定掩体在哪里?同样,“逃跑”到底是什么意思?最安全的地方是哪里?或者在一个RTS游戏里,我们可能希望让部队攻击敌方防御的薄弱点,那么确定最薄弱点在哪里的便捷方法又是什么?
所有这些都可以视为地理查询。因为我们要询问有关环境的形状(shape),形式(form)以及其中实体位置的问题。我们的游戏拥有所有的这些数据,但要弄清楚这些数据却相当棘手。例如,如果我们想找到敌人防御的薄弱点,单单选择最薄弱的建筑物或防御工事的位置是远远不够的,因为它两侧可能有两座强大的武器系统!为了更好地了解情况,我们需要一种考虑到局部区域的方法。
影响图正是一种针对此类问题而设计的数据结构。它代表一个实体可能对其周围区域产生的“影响力”,并通过组合多个实体的影响来呈现出更真实的整体格局。在实现方面,我们通过覆盖2D网格来近似估算游戏世界,在确定实体所在的方格之后,我们可以将其影响力得分(表示游戏模型的某个方面)应用于该方格及其周围的格子。我们将这些值累积在同一网格中以获得整体形势。然后我们可以通过各种方式查询网格来了解世界,做出有关位置和目的地的决策。
以“对手防御的最薄弱点”为例:敌方有一面城墙,我们想派士兵来进攻。但墙后有3个投石机,左侧2个,右侧1个。如何选择进攻的最佳位置呢?
首先,对于每个投石机攻击范围内所有方格,我们赋予+1防御分。在一个投石机影响图上绘制得分的格子,如下所示:
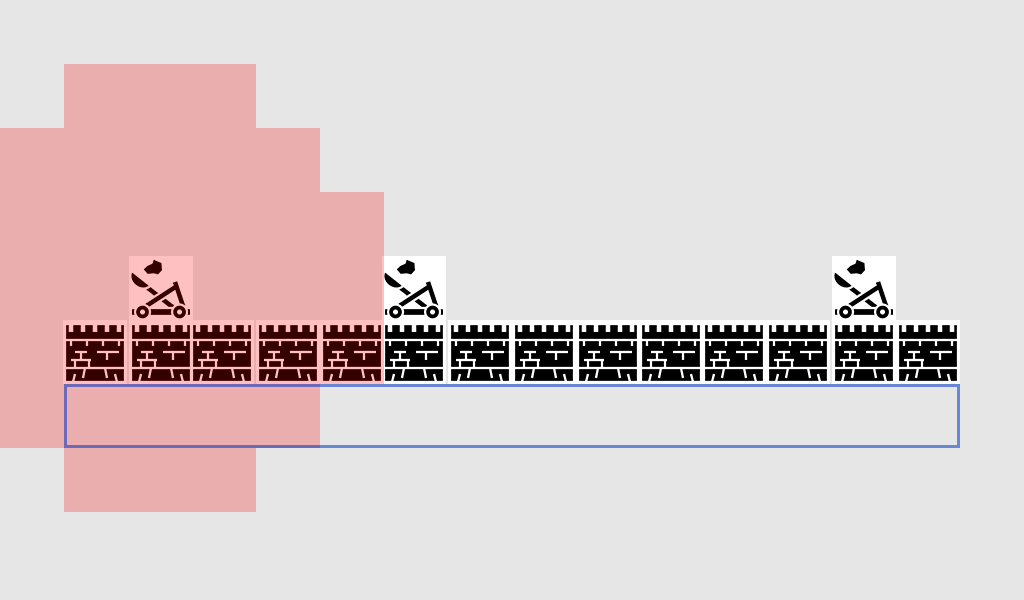
蓝色框包含了所有可以攻击城墙的位置。红色方块表示投石机的+1影响力,意味着它们可以攻击这些位置,从而对入侵单位构成危险。
如果我们现在加入第二个投石机的影响力:
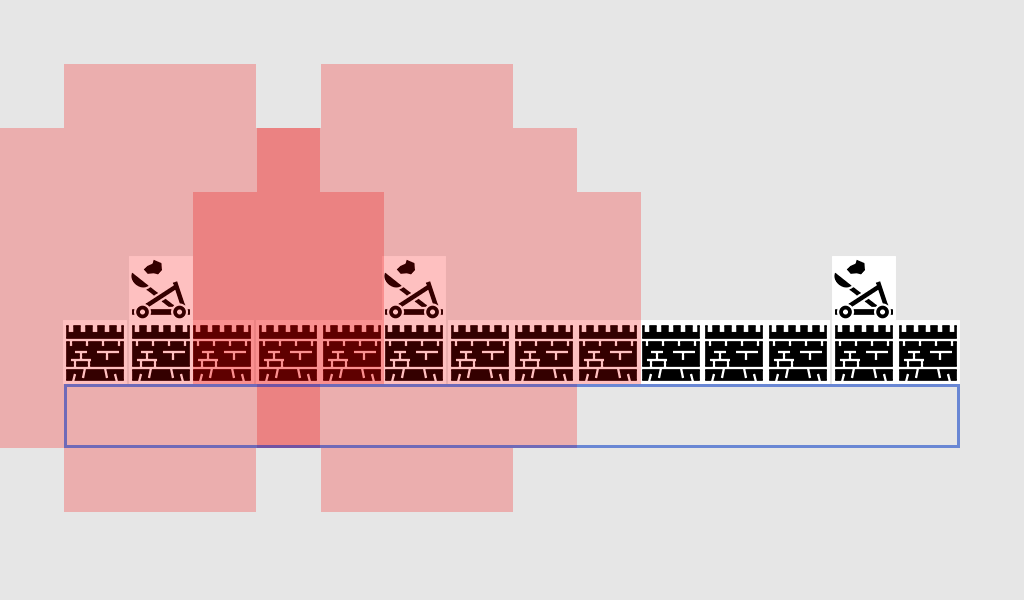
现在出现了一片深色区域,因为两个投石机的影响力重叠,这些方块的影响力得分为+2。蓝色区域内的+2方格是攻城时特别危险的地方!让我们再加上最后一个投石机的影响力:
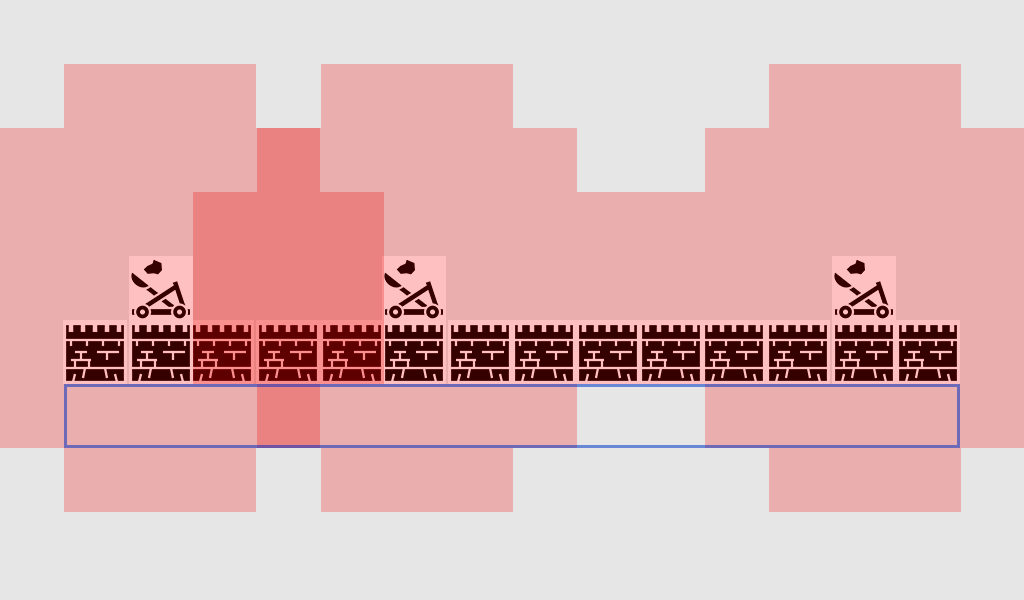
[图标:CC-BY]
现在,我们可以充分了解投石机覆盖的区域。在我们的潜在攻击区域中,1个方格有投石机的+2影响力,11个方格有+1影响力,但有2个方格没有投石机的影响力。这正是我们首选的攻击位置!在这里我们可以攻击城墙而不用冒着投石机开火的危险。
这里影响图的优点是,它将具有几乎无限位置可能性的连续空间转换为可以很快推导出的离散位置集合。
尽管如此,我们仅仅通过选择少量攻击位置就可以获得这个好处。为什么我们选择使用影响图,而不是手动检查每个位置到每个炮塔的距离?
首先,影响图的计算可能非常便宜。一旦用影响力分数绘制好地图,除非其中的实体移动,否则根本不需要更改。这意味着你不必一直执行距离计算或持续遍历每个可能的单位。我们只需一次将信息“烘焙”到地图中,即可任意多次查询。
其次,我们可以叠加组合多个影响图,从而实现更复杂的查询。例如,要找到一个安全的逃生地点,我们可以用敌人的影响图减去我们友军的影响图。可以看出,安全的位置就是负得分较高的方格。
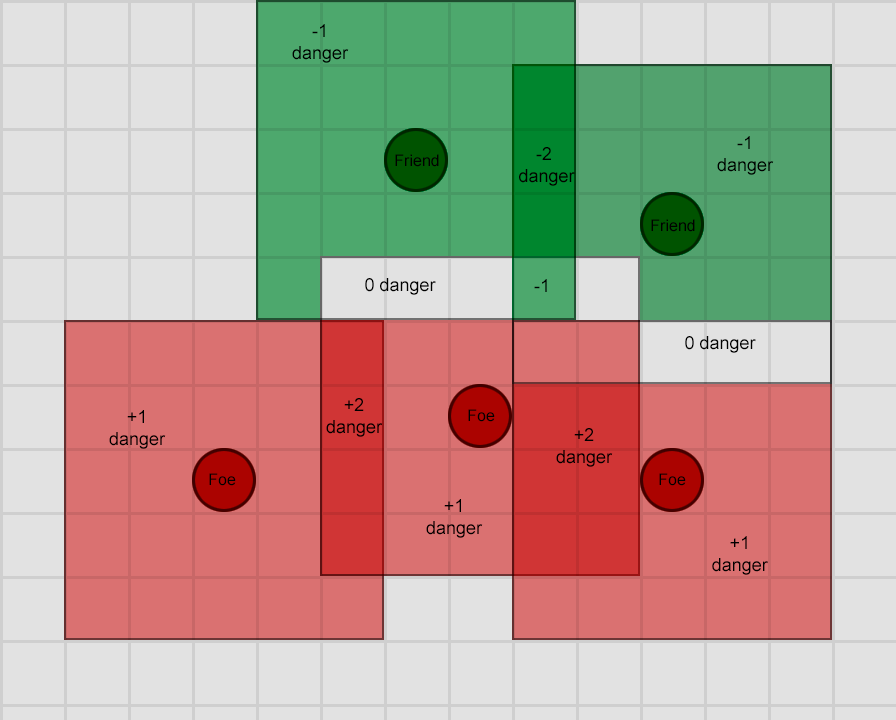
红色越多表示危险越大,绿色越多则表示安全性越高。它们重叠的区域可以完全或部分抵消,可以反映出冲突的影响区域。
最后,我们可以很容易地在游戏世界里绘制影响图,将其可视化。如果游戏设计师需要根据可见属性来调整AI,这对他们有很大帮助,而且可以通过实时查看来了解AI为何做出相应的决策。
结论
希望这篇文章能够让你对游戏AI一个广泛的了解,包括一些最常用的工具和方法及其应用场景。目前尚未涵盖其他多种技术(不太常用但可能同样有效),包括:
- 优化任务的算法,包括爬山(hill-climbing),梯度下降(gradient descent)和遗传算法(genetic algorithm)
- 对抗搜索/规划算法,例如极小化极大算法(Minimax)和Alpha-beta剪枝(Alpha–beta pruning)
- 分类技术,例如感知器(perceptron),神经网络(neural networks)和支持向量机(support vector machine, SVM)
- 处理代理感知和记忆的系统
- AI体系结构方法,例如混合系统,包容式架构(subsumption architecture),以及其他构建AI系统的方法
- 动画工具,例如运动规划(motion planning)和运动匹配(motion matching)
- 性能优化因素,例如细节级别(level of detail),任意时间算法(anytime algorithm)和时间分片(timeslicing)
若要阅读更多有关这些主题以及上面详细介绍的主题,以下来源或许会有所帮助。
- GameDev.net上,您可以找到人工智能文章和教程参考以及人工智能论坛。
- AiGameDev.com 包含许多与游戏开发相关的AI主题相关的演讲和文章。
- GDC Vault包含GDC AI峰会的演讲,许多演讲可免费获得。
- 同样,AI Game Programmers Guild提供许多指向该峰会过去论文和演讲的链接。
- AI研究人员和游戏开发人员Tommy Thompson拥有一个YouTube频道:AI and Games,专门用于解释和探索商业游戏中的AI。
书籍中可以找到许多最有价值的资料,包括以下书籍:
- Game AI Pro 系列是简短文章的合集,这些文章阐述了如何实现某些特定功能,或者如何解决某些特定问题等。访问 http://www.gameaipro.com,可以获取一些早期书籍的免费摘录。
- Game AI Pro: Collected Wisdom of Game AI Professionals
- Game AI Pro 2: Collected Wisdom of Game AI Professionals
- Game AI Pro 3: Collected Wisdom of Game AI Professionals
- AI Game Programming Wisdom系列是Game AI Pro书籍的前身,其中包含稍旧的技术,但在今天几乎仍然普遍适用。份数很少,因此请留意数码副本或特价商品!
- 人工智能:一种现代的方法,这是了解人工智能通用领域的标准教科书之一。这本书不是专门针对游戏的,而且很多内容比较难懂,但是它对人工智能领域作了一个非常赞的总览,并介绍了许多游戏AI的基础知识。
除此之外,还有一些由行业专家撰写的关于通用游戏AI的优秀书籍,很难一一列举,你可以阅读相关书评并选择适合自己的书。