游戏AI入门指南(Part 2)
原文: The Total Beginner’s Guide to Game AI 作者: Ben Sizer 译者: Anthony Han
进阶决策
虽然简单的反应型系统已十分强大,但在很多情况下还是不够完善的。有时我们想根据代理当前正在做的事情做出不同的决定,并将其作为一个条件来使用,那么就会有些不太方便。有时因为条件太多,导致无法在决策树或脚本中表达清楚。有时在决定下一步行动之前,需要先思考再评估情况将如何变化。对于这些问题,我们需要更复杂的解决方案。
有限状态机
有限状态机(Finite State Machine,简称FSM)是一个花哨的专用术语,来描述这样的东西:举例来说,某个AI代理目前处于几种可能的状态中,它可以从一个状态转换到另一个状态。而这些状态的数量有限,因此得名。现实生活中的例子如一组交通信号灯,它会从红色变成黄色,再变成绿色,然后再变回红色。不同的地方有不同的亮灯顺序,但原理是相同的——每个状态代表某种事物(例如“停止”,“前进”,“尽可能停止”等),任何时候都仅处于一种状态,并且它会根据简单的规则从一个状态过渡到另一个状态。
这非常适用于游戏中的NPC。一个警卫可能具有以下状态:
- 巡逻
- 攻击
- 逃跑
当状态改变时,你可能会想到这些规则:
- 如果警卫看到敌人,就立即攻击
- 如果警卫正在攻击但无法再看到敌人,那么返回巡逻
- 如果警卫正在攻击但受了重伤,那么开始逃跑
这个规则很简单,你可以直接把它写成硬编码的if语句,用一个变量来保存警卫的状态,并进行各种检查:查看附近是否有敌人,警卫的健康状况如何等等。但如果我们要添加更多的状态:
- 空闲(巡逻期间)
- 搜寻(刚才发现的敌人躲起来时)
- 求助(发现敌人,但因为敌人太强而无法独自作战时)
通常在每个状态下可做出的选择是有限的——例如当警卫的健康状况不佳时,他们可能不想寻找敌人。
如果最终用一长串的“if (x and y but not z) then p”来表示,就显得有些笨拙了。如果以一种通用统一的方式来实现状态之间的转换,应该会有所帮助。为此我们要考虑所有状态,并且在每个状态下,列出到其它状态的所有转换和条件。我们还要指定一个初始状态来决定在条件适用之前从哪里开始。
| 状态 | 转换条件 | 新的状态 |
|---|---|---|
| 空闲 | 已空闲10秒钟 | 巡逻 |
| 敌人可见 且 敌人太强 | 寻求帮助 | |
| 敌人可见 且 自己生命值 高 | 进攻 | |
| 敌人可见 且 自己生命值 低 | 逃跑 | |
| 巡逻 | 完成巡逻路线 | 空闲 |
| 敌人可见 且 敌人太强 | 寻求帮助 | |
| 敌人可见 且 自己生命值 高 | 进攻 | |
| 敌人可见 且 自己生命值 低 | 逃跑 | |
| 进攻 | 没有 敌人可见 | 空闲 |
| 自己生命值 低 | 逃跑 | |
| 逃跑 | 没有 敌人可见 | 空闲 |
| 搜寻 | 已搜寻10秒钟 | 空闲 |
| 敌人可见 且 敌人太强 | 寻求帮助 | |
| 敌人可见 且 自己生命值 高 | 进攻 | |
| 敌人可见 且 自己生命值 低 | 逃跑 | |
| 寻求帮助 | 友军可见 | 进攻 |
| 起始状态: 空闲 |
这个表格称为状态转换表,是一种对FSM全面(又枯燥)的描述方式。根据这些数据还可以绘制图表,从而得到NPC行为如何随时间变化的全面可视化概览。
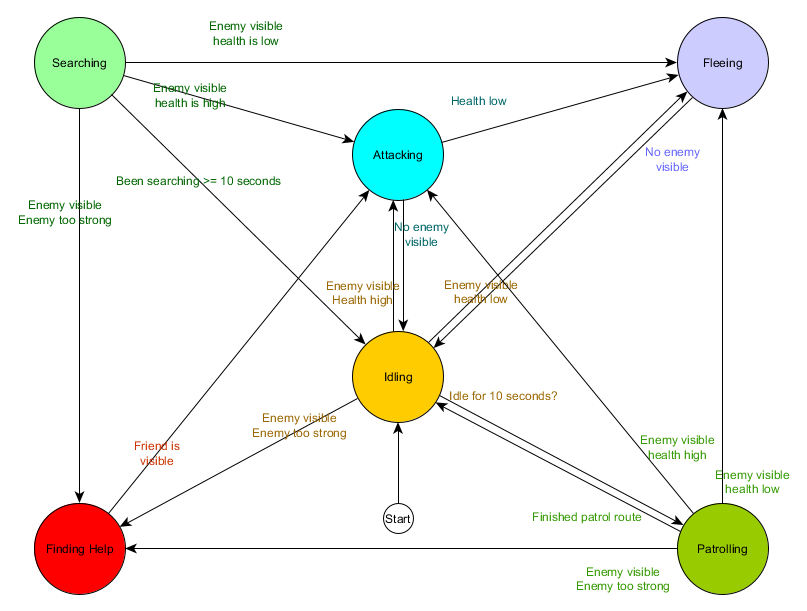
这张图抓住了代理根据其所处的状态进行决策的本质,如果箭头旁边的条件为真,则每个箭头都表示状态之间的转换。
在每次更新(update)或每一刻(tick),我们都要检查代理的当前状态,查看转换列表,如果满足转换条件,则变更为新状态。空闲状态时则要每帧检查计时器,判断10秒是否已到,如果已到,则触发转换到巡逻状态。同样,攻击状态则会检查代理的生命值是否不足,如果是,则转换到逃跑状态。
如此便完成了处理状态之间的转换。但是,与状态本身相关的行为又如何呢?就执行给定状态的实际行为而言,通常有两种“钩子”将行动附加到有限状态机上:
- 针对当前状态定期执行的行动,例如每一帧。
- 从一种状态过渡到另一种状态时所采取的行动。
第一种类型的示例:巡逻状态将每帧继续沿巡逻路线移动特工。“攻击”状态也会每帧尝试发起攻击或移动到可能的位置等等。
对于第二种类型,想想“如果敌人可见并且敌人太强→寻找帮助”的过渡。代理可以选择得到帮助的位置,并存储该信息,以便“求助”状态知道要去哪里。同样,在“求助”状态下,一旦得到帮助,代理便会转换回“攻击”状态,但此时它将要告诉队友有关威胁的信息,因此可能会在该状态上执行 “NotifyFriendOfThreat” 操作过渡。
与此类似,我们可以从 感知/思考/行动(Sense/Think/Act) 角度审视有限状态机(FSM)系统。“感知”体现在状态转换使用的数据上。“思考”体现在每个状态可用的转换上。“行动”的实现则是由状态间的转换,或者状态内定期采取的动作来完成的。
这个基本的系统能够良好运行,虽然有时状态转换条件的连续轮询可能带来较大开销。例如,如果每个代理必须在每一帧进行复杂的计算来确定是否可以看到任何敌人,以便决定是否从巡逻转换到进攻,如此可能会浪费大量CPU时间。如前所述,我们可以将世界状态中的重要变化视为可以在事件发生时进行处理的“事件”。所以你不必让状态机每帧必须检查“我的代理可以看到玩家吗?”诸如此类的转换条件,而是用一个独立的能见度系统以较低频率执行这些检查(例如,每秒5次),并在条件满足时发出“发现玩家”事件。将事件传递给状态机,再给状态机设置一个“收到‘发现玩家事件’”的过渡条件,并相应地响应该事件。除了有一些不明显的响应延迟(但更为真实),最终行为是相同的,但由于将系统中的感知部分独立出来,因此性能会更好。
分层状态机
有限状态机各方面都还不错,但使用大型状态机可能会遇到比较尴尬的局面。如果我们想用MeleeAttacking(近战攻击)和RangedAttacking(远程攻击)状态来扩展进攻状态,就必须修改每个状态的过渡条件,才能让这些状态转换到新的状态。
你可能还会注意到,示例中有很多重复的过渡。大多数处于“空闲”状态的过渡与处于“巡逻”状态的相同,特别是添加更多类似状态时,最好不必做重复的劳动。将空闲和巡逻归类为某种“非战斗”的共享类别中,这个类别里只有一组转换到战斗状态的共享转换。如果将其表示为状态本身,则可以将“空闲”和“巡逻”视为该状态的“子状态”,使得我们可以更有效地表示整个系统。例如,为新的“非战斗”子状态使用单独的转换表:
主要状态:
| 状态 | 转换条件 | 新的状态 |
|---|---|---|
| 非战斗 | 敌人可见 且 敌人太强 | 寻求帮助 |
| 敌人可见 且 自己生命值 高 | 进攻 | |
| 敌人可见 且 自己生命值 低 | 逃跑 | |
| 进攻 | 没有 敌人可见 | 非战斗 |
| 自己生命值 低 | 逃跑 | |
| 逃跑 | 没有 敌人可见 | 非战斗 |
| 搜寻 | 已搜寻10秒钟 | 非战斗 |
| 敌人可见 且 敌人太强 | 寻求帮助 | |
| 敌人可见 且 自己生命值 高 | 进攻 | |
| 敌人可见 且 自己生命值 低 | 逃跑 | |
| 寻求帮助 | 友军可见 | 进攻 |
| 起始状态: 非战斗 |
非战斗状态:
| 状态 | 转换条件 | 新的状态 |
|---|---|---|
| 空闲 | 已空闲10秒钟 | 巡逻 |
| 巡逻 | 完成巡逻路线 | 空闲 |
| 起始状态: 空闲 |
图表形式如下所示:
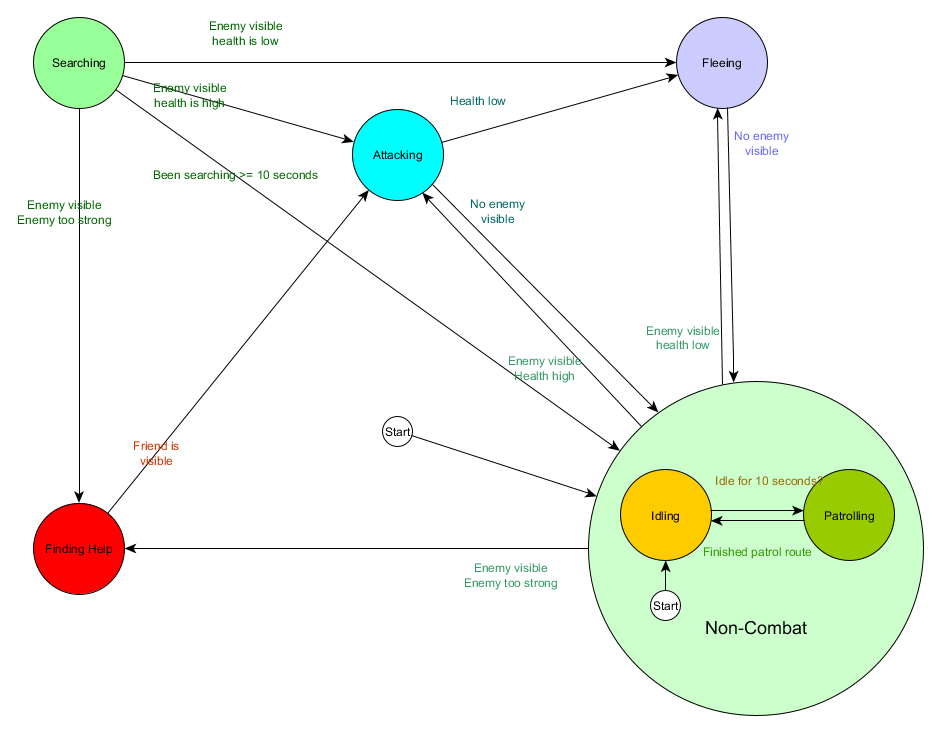
可以看出,除了用一个非战斗状态代替了巡逻和空闲外,基本上是同样的系统。而且这个新状态本身也是一个状态机,具有巡逻和空闲2个子状态。因为每个状态可能包含子状态的状态机(而这些子状态也可以包含状态机,可根据需求添加),所以我们称之为分层有限状态机(Hierarchical Finite State Machine,简称HFSM)。通过对非战斗行为进行分组,我们分离出了一堆冗余的过渡。对于任何具有共同转换条件的新状态,我们都可以使用这个做法。例如,如果将来我们将“进攻”状态扩展为“近战攻击”和“导弹攻击”状态,那么它们会成为子状态,根据与敌人的距离和弹药量在彼此之间进行转换,但共享根据生命值水平等的退出过渡条件。可以很容易地用这种方式表示复杂的行为和子行为,并减少重复的转换。
行为树
通过 分层有限状态机(HFSM) 我们能够以相对直观的方式,构建相对复杂的行为集。但是这个设计中存在一个小问题:以状态转换规则构成的决策系统与当前状态紧密束缚在一起,这正是许多游戏所需要的。仔细使用状态层次结构可以减少重复转换的数量,但有时无论处于哪个状态或几乎在所有状态,你的规则都要适用。打个比方,如果代理的生命值降低到25%时,则无论其当前处于战斗状态,空闲状态、谈话状态或者其它任何状态,你可能都希望他逃跑。而且你也不希望自己需要时刻牢记:将来新增每个状态时,都一定把这个条件添加进去。
针对这种情况,一个理想的系统应该将决策过程和状态本身分离,这样你只需要在一个位置进行更改,仍然能够正确转换状态,这就是行为树的应用场景。
实现行为树有几种不同的方式,但是本质上是相同的,而且与前面提到的决策树非常相似:从“根节点”开始运行,树的节点用来表示决策或行动。但还有一些关键区别:
- 节点的返回值有三种:成功(工作已完成),失败(无法运行)或正在运行(仍在运行并且尚未完全成功或失败);
- 决策节点不需要在两个方案之间进行选择,而是使用“装饰(Decorator)”节点,该节点具有一个子节点。如果“成功”,它们将执行其单个子节点。装饰节点通常包含条件,这些条件决定是成功(执行子树)还是失败(不执行任何操作),条件符合时还可以返回“正在运行”;
- 采取行动的节点将返回
正在运行,表示行动正在进行;
这些节点可以通过组合来生成很多复杂的行为,同时又能表述得非常简洁。例如,我们可以将前面示例中的警卫分层状态机重写为行为树:
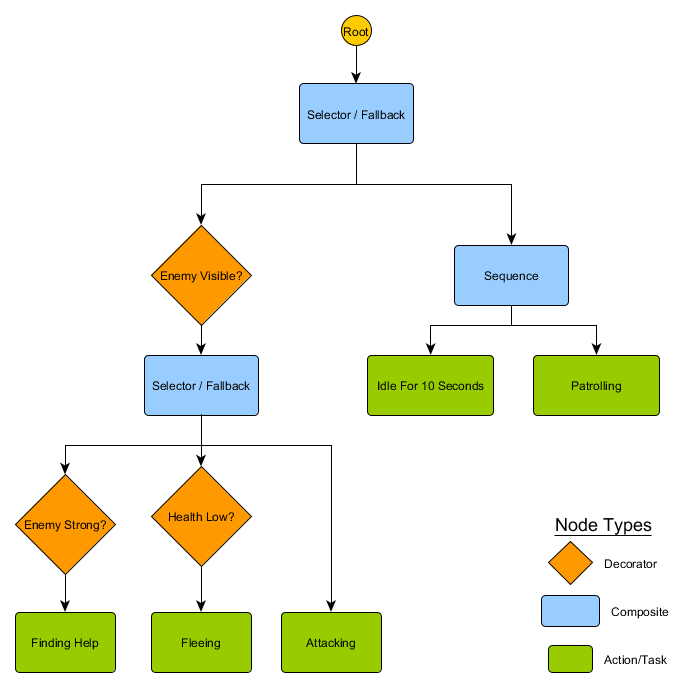
通过这种结构,从空闲或巡逻状态到进攻状态或其它任何状态时,无需进行显式的转换——如果从上到下从左到右地遍历树,就可以得到当前情况下的最佳决策。如果看见敌人且角色自身的生命值很低,那么行为树会在“逃跑”节点处停止执行,不管其先前执行的是哪个节点——巡逻,空闲还是进攻等。
你可能会注意到,当前没有从巡逻状态返回到空闲状态的转换——这里无条件装饰节点该出场了。一个常见的装饰节点是“重复(Repeat)节点”——它不包含条件,只是拦截子节点返回“成功”并再次运行,返回“正在运行(Running)”。新的行为树如下所示:
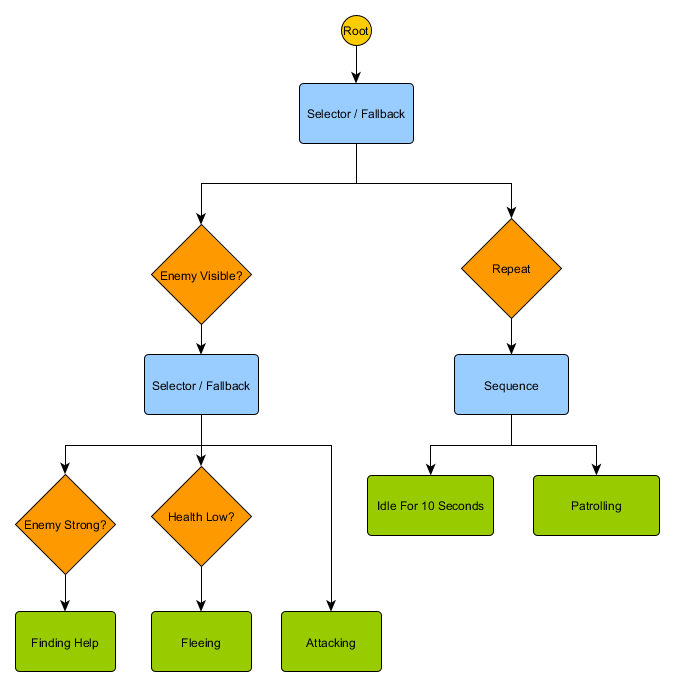
行为树非常复杂,因为通常有很多不同的方法来绘制树,而且找到一个合适的装饰节点和复合节点的组合方式也很棘手。同时它还存在以下问题:多久检查一次树(我们要每帧遍历,还是仅在条件发生变化时才遍历?)以及如何存储与节点有关的状态(如何知道已经空闲了10秒钟?为了正确地执行序列节点,如何知道上次执行的节点?),因此存在许多不同的实现。例如某些系统(如 Unreal Engine 4 的行为树系统)用内联装饰器取代了装饰器节点,仅在装饰器条件发生变化时才重新评估树,并提供“服务”来附加到节点上并提供定期更新,即使没有重新评估树也是如此。行为树是非常强大的工具,但是学会有效地使用它们,特别是面对多种多样的实现时,可能会让人望而却步。
(译注:关于行为树的详细介绍,可参考《AI行为树的工作原理》)
基于效用的系统
有些游戏希望拥有许多不同的动作,因此要具备更简单,集中的转换规则等优点,但又不需要行为树实现的表达能力。除了明确轮流做出选择,或者从树的众多节点动作中做出选择,或许可以简单地检查所有动作,并从中挑选出最合适的动作?
这就是基于效用 (Utility-based) 的系统——代理有各种供其使用的动作,它根据每个动作的相对效用,从中选择一个来执行。效用是一个任意度量,用来衡量代理执行某个动作的重要性或期望程度。根据代理的当前状态及其环境,编写效用函数 (utility function) 来计算动作的效用值,代理根据效用值来选择最相关的状态。
再次需要说明的是,它与有限状态机非常相似,只是状态转换由每个潜在状态(包括当前状态)的分数决定。请注意,我们通常选择得分最高的动作来转换状态(或留在其中,如果已经执行了该动作的话),但是对于更多种类的选择,它也可以是加权随机(weighted random)选择(有利于得分最高的动作,但可以选择其他一些动作),或者从前5个(或任何其他数量)中选择一个随机动作等等。
典型的效用系统会为效用值设置一个范围——例如,0(完全不理想)到100(完全理想),并且每个动作可能有一组影响该值计算的考量条件 (consideration)。回到警卫的例子,我们这样来表示:
| 动作 | 效用计算 |
|---|---|
| 寻求帮助 | If 敌人可见 and 敌人太强 and 自身生命值 低 return 100 else return 0 |
| 逃跑 | If 敌人可见 and 自己生命值 低 return 90 else return 0 |
| 进攻 | If 敌人可见 return 80 |
| 空闲 | If 当前空闲 and 已处于当前状态10秒, return 0, else return 50 |
| 巡逻 | If 到达巡逻终点, return 0, else return 50 |
此处最要注意的重点之一就是:动作之间的转换是完全隐式的——任何状态都可以合法地跟随其它状态。同样地,动作优先级也隐含在返回的效用值中。如果敌人是可见的,敌人又很强,而且角色的生命值比较低,那么“逃跑”和“求助”都返回较高的值,但“求助”得分更高。同样非战斗行动永远不会返回超过50,因此它们总是会被战斗行动所压倒。行动及其效用计算必须要考虑到这一点。
示例中动作效用值是一个固定值或两个固定值之一。实际的系统通常会从多项连续的数值范围内取出数值,并计算出分数。例如,如果代理的生命值较低,则“逃跑”动作可能会返回较高的效用值,而如果敌人很难击败,则“进攻”动作可能会返回较低的效用值。这样在代理觉得自己没有足够的生命值来对抗敌人的情况下,“逃跑”动作就可以优先于“进攻”。这使得动作的相对优先级可以根据任意标准进行变化,从而使这种方法比行为树或有限状态机更加灵活。
每个动作通常在计算效用时都有很多条件。为避免对所有内容进行硬编码,可以使用脚本语言或以易于理解的方式编写一系列的数学公式。有关更多信息,请参见Dave Mark的讲座和演示。
有些模拟人物日常活动的游戏(如《模拟人生》)增加了额外的计算层,其中代理具有一组影响效用得分的“动力”或“动机”。例如,如果角色有饥饿动机,这个动机可能会随着时间而定期上升,随着时间的流逝,EatFood 动作的效用得分会越来越高,直到角色执行了这个动作,降低其饥饿水平。然后 EatFood 动作返回到零或接近零的效用值。
基于评分系统选择动作的方法非常直观,所以将基于效用的决策作为其他AI决策过程的一部分,而不是完全替代它们,显然是普遍可行的。决策树可以查询其两个子节点的效用分数,并选择得分较高的一个。同理,行为树可以具有一个 Utility 组合节点,该节点使用效用分数来决定执行哪个子节点。
移动与导航
之前的那些示例,要么是可以左右移动的球拍,要么是可以巡逻或进攻的警卫。但是我们到底如何精确地控制代理在一段时间内的移动呢?如何设置速度?如何避开障碍?如果目的地不能直接到达时,如何规划路线?下面我们就来探究一下。
引导(Steering)
一般来说,我们会认为代理有一个速度值,包含其移动的速度和方向。可以用米/秒,英里/小时,像素/秒等单位来表示。回顾前面的“感知/思考/行动”循环,我们可以设想“思考”时选择一个速度,然后“行动”时将这个速度应用于代理,让它移动到其他地方。游戏通常会有一个物理系统来执行这项任务,检查每个实体的速度值并相应地调整位置,因此可以将这个工作委托给该系统,而让AI自行决定代理的速度。
如果一个代理希望去某个地方,那么就让代理以某个速度沿该目标方向移动。可用用一个这样简单的公式:
wanted_travel = destination_position – agent_position
假设在一个2D世界里,一个代理位于坐标(-2,-2),目的地坐标在(30,20)——大致东北方的某个地方,代理到达那里所需的行程为(32,22) 。假设米/秒为单位——如果代理的速度为5米/秒,那么将速度向量进行特征缩放,得到值约为(4.12,2.83)。基于这个速度值移动,代理就会像我们期望的那样在8秒后到达目的地。
(译注:可以先对(32,22)进行 normalization 处理,得到单位向量(0.824,0.5665),乘以速度标量5m/s,可得速度向量(4.12,2.83))
我们可以随时根据需要重新计算速度。如果代理到目标只有原距离一半,则所需的行程将是原长度一半,但是一旦缩放到代理的最大速度5m/s,速度就会相同。同样适用于正在移动的目标(合理范围内),允许代理在移动时进行校正。
通常我们需要更多的控制权——比如我们可能想在开始时缓慢地提高速度,表示一个人从静止到移动,从步行再到奔跑。我们让它在到达目标时也进行相同的动作,让它在接近目的地时缓慢停止。这通常由所谓的“引导行为(steering behaviours)”来处理,每个行为都有特定的名称,例如“寻找”,“逃跑”,“到达”等。这些方法的思想是,根据将代理的位置和当前速度,并将加速度应用于代理的速度上,从而产生向目标移动的不同方式。
每种行为的目的都会有一些不同。“寻找”和“到达”是将代理移向目标点的方法。”避障“和”分离“帮助代理采取较小的调整动作,绕过其与目的地之间的小障碍。”排列(Alignment)“和”凝聚(Cohesion)“则可以使代理一起移动,用来模拟成群的动物。通常可以将这些不同的引导行为中的任意数量加在一起(一般作为加权总和),生成一个将这些不同的关注点考虑在内的合计值,并最终生成一个输出向量。举例来说,典型的角色代理会将“到达”行为与“分离”行为,以及“避障”行为一起使用,以远离墙壁和其他代理。这种方法在不太复杂或不拥挤的开放环境中效果很好。
然而在更具挑战性的环境中,简单地将行为的输出加在一起效果并不是很好——可能会在越过某个东西时速度缓慢,也可能在“到达”行为想要越过障碍却又被障碍被卡住时,“避障”行为却将代理推回原位。所以比起把所有值加在一起,考虑引导行为的复杂变化来得更有意义。其中有一个方法是倒过来考虑引导行为——与其让每种行为给我们一个方向,再将它们结合在一起产生一个最终结果(这个结果可能并不能满足条件),不如在几个不同方向上考虑引导行为(比如8个罗经点,或者代理前方的5-6个方向等等),然后选出其中最佳的一个。
尽管考虑到这么多,但是在一个到处是死胡同的复杂环境里,该如何选择路线?我们还需要更高级的东西,接下来就谈谈这些内容。
寻路算法
在开阔区域(如足球场或竞技场)进行简单移动非常容易。这种情况下,从A点到B点只要沿直线前进,通过一些细微调整来避开障碍物即可。如果通向目的地的路线更复杂时,应该怎么办呢?这是我们需要“寻路”的地方,寻路算法可以检查世界环境并选择合适的路线,最终让代理到达目的地。
最简单的寻路:在一个网格上,检查与你相邻的每个可前往的方格。当发现包含目的地时停止搜索。沿着目的地从每个方格到上一个方格的路线走,直到到达起点为止,就得到了路线。否则,对先前邻居的可及邻居重复此过程,直到找到目的地或遍历完所有方格(说明没有可用的路线)。这就是正式使用的“广度优先搜索(Breadth-first search, BFS)”算法 (Breadth-First Search algorithm,通常缩写为BFS),因为它会每次在向外移动搜索之前检查所有方向(因此称为“广度”)。搜索空间就像波浪一样,向外扩散直到碰到要寻找的位置。
这是一个搜索的简单示例。搜索区域会逐步扩展,直到包含目标点为止,然后再追溯通往起点的路径。
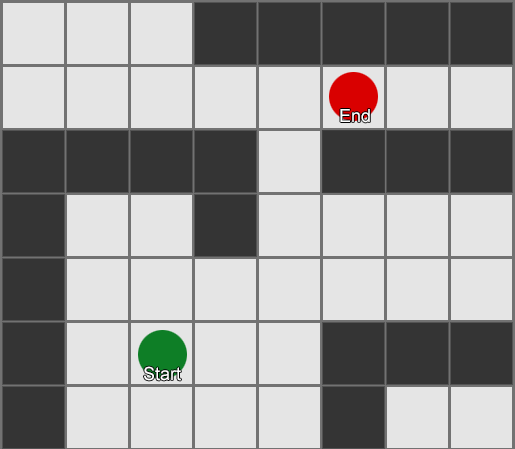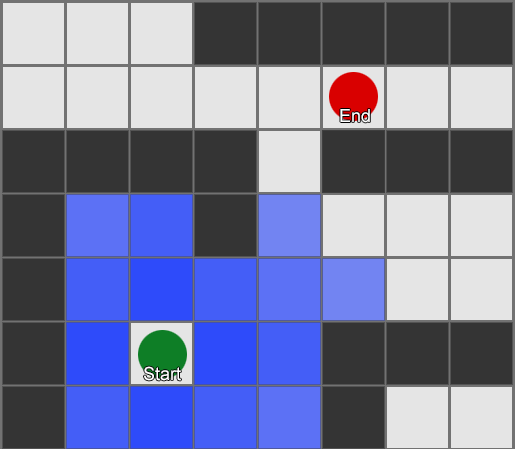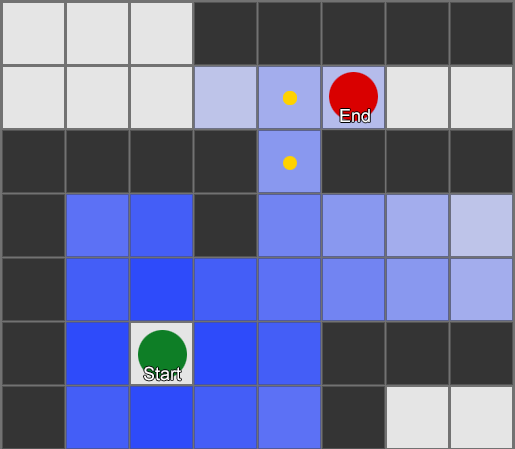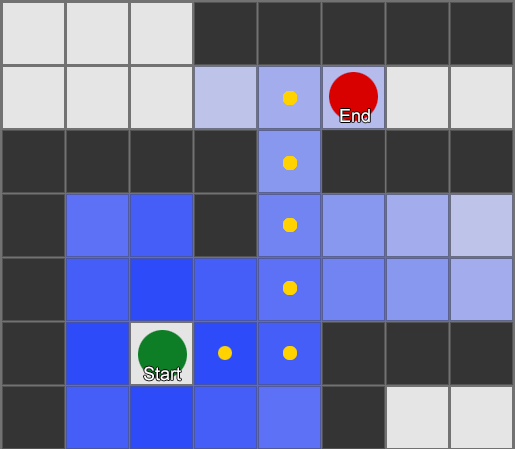
最终结果是你得到了组成最终路线的方格列表。这通常被称为“路径(path)”(算法也因此得名“寻路(pathfinding)”),但你也可以将其视为一个计划,因为它代表了最终要到达目的地而要经过的一系列地点。
假设我们知道游戏里每个方格的位置,那么可以使用前面提到的引导行为沿着路径移动——首先从“起始节点”到“节点2”,然后从“节点2”到“节点3”,依此类推。最简单的方法是转到下个方格的中心,但是更流行的方案是转到当前方格和下个方格之间的边缘中间。这样代理就可以在急转弯的位置抄近路,移动时显得更真实。
不难发现,BFS算法有些浪费,因为它在“错误”方向探索的方格与“正确”方向一样多。它也没有考虑到移动代价(movement costs),有的方格比其它方格的花费更多。所以就需要更复杂的 A*(发音为“A star”) 算法出场了。它的处理过程与广度优先搜索类似,不同之处在于:它不是盲目探索邻居,然后是邻居的邻居,然后是邻居的邻居的邻居等等,它将所有这些节点放入列表中并进行排序,找到它探索的下一个节点,这个节点始终是它认为最有可能达成最短路线的那个节点。
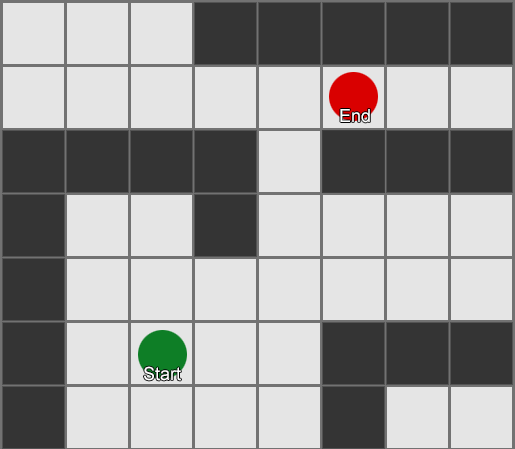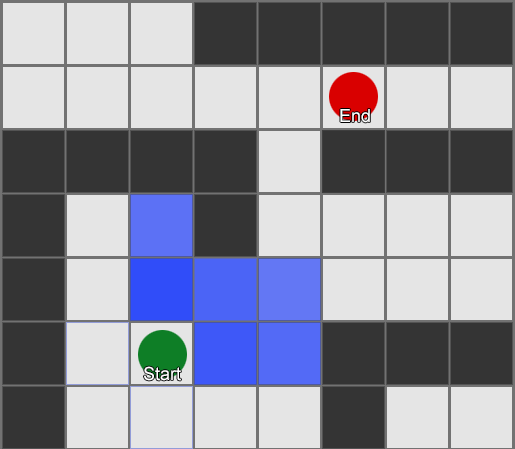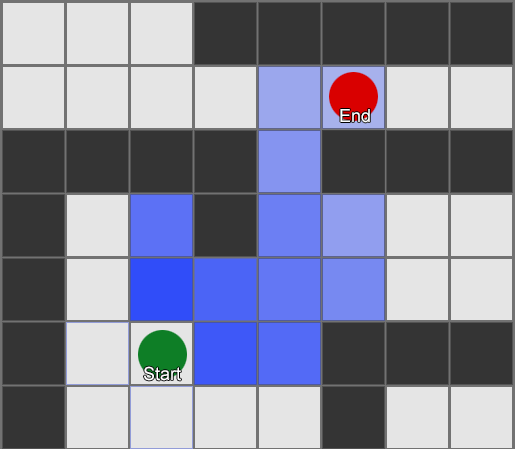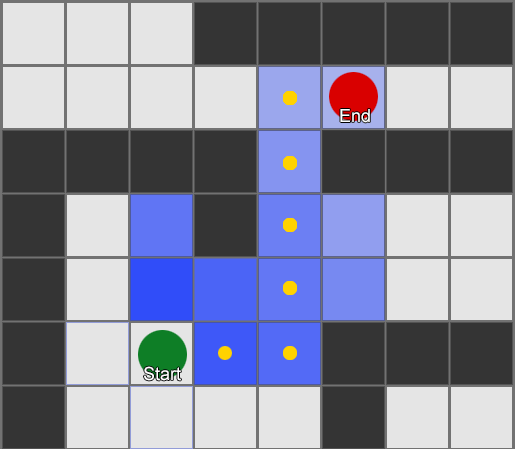
在这个示例中,我们展示了A*算法每次检查一个方格,每次选择一个最佳的相邻方格。最终的路径与广度优先搜索相同,但是在此过程中检查的方格更少了,在关卡比较复杂的游戏里,性能会有很大的差异。
没有格子的寻路
前面的示例使用了覆盖在游戏世界里的网格,并根据方格绘制了路线。但是大多数游戏都没有布置在网格上,因此覆盖网格可能无法形成真实的运动模式。可能还要在方格的大小上做出妥协——太大,不能恰当表示狭小的走廊或转弯,而太小又意味着要搜索成千上万个方格,并且会消耗很长时间。那么究竟有没有其它可行方案呢?
首先要意识到的是,网格在数学形式上为我们提供了连接节点的“图(graph)”。A*(和 BFS)算法实际上是在图上运行的,根本不关心网格。因此我们可以将节点放置在游戏世界里的任意位置,并规定在任意两个相连的节点之间,以及起点和终点与至少一个节点之间存在一条可行走的直线,算法会像之前一样良好运行——实际上会更好,因为要搜索的节点更少了。这通常被称为“航路点”系统,因为每个节点代表着游戏世界里的重要位置,可以成为任意路径的组成部分。
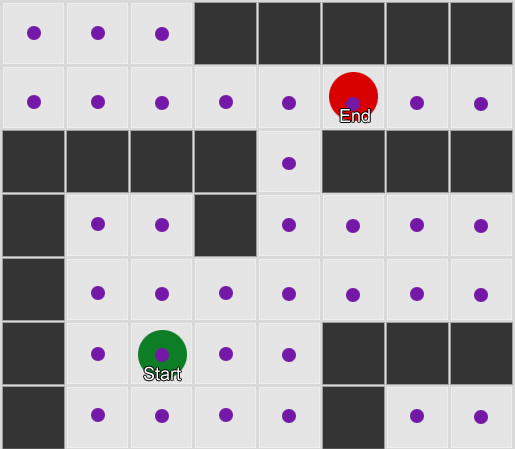
示例1:每个方格作为一个节点。从代理所在的节点开始搜索,并在目标方格的节点处结束。
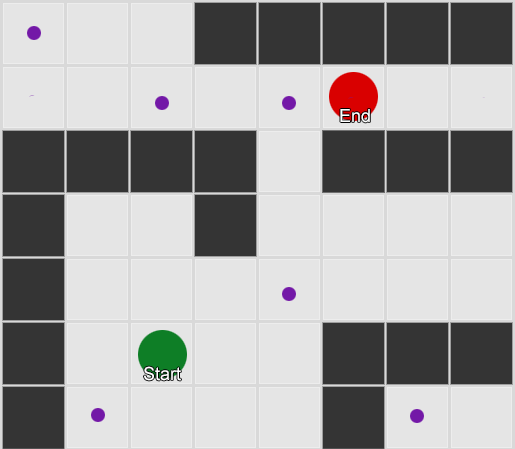
示例2:少得多的节点(航路点)。从代理开始搜索,经过必要的几个航路点,然后行进到终点。请注意,移动到玩家西南的第一个航点是一条低效的路线,因此通常需要对以此方式生成的路径进行一定程度的后处理(例如,发现该路径可以直接进入东北的航路点)。
(译注:这里有一点没明白,使用A*应该不会选择起点西南的那个航点,作者为什么这么说?)
这是一个相当灵活而强大的系统。但在确定航路点的位置和方式时要格外小心,否则代理可能无法查看其最近的航路点并开始寻路。如果我们能根据游戏世界的几何结构自动生成航路点,那就太好了。
“导航网格(navmesh)”就应运而生了。它是 “navigation mesh” 的简称,通常为二维的三角形网格,大致覆盖了游戏世界里允许代理行走的区域。网格中的每个三角形都是图中的一个节点,并最多有3个相邻的三角形,这些三角形成为图中的相邻节点。
这张图片是Unity引擎的一个示例——它分析了游戏世界的几何结构,并生成相近的导航网格(浅蓝色)。导航网格中的每个多边形都是代理可以站立的区域,代理可以从一个多边形移动到与其相邻的任何多边形。(在此示例中,考虑到代理的半径超出了代理的标称位置,这些多边形的宽度比其所依赖的地面要窄。)

我们依然可以使用 A* 来搜索通过网格的路线,最终会得到一条近乎完美的路线,该路线可以考虑到整个游戏世界的几何结构,但不需要过多的冗余节点(例如网格),也不需要通过人工来生成航点。
寻路是一个非常广泛的主题,尤其是当你自己编写底层细节代码时,往往有很多不同的解决方案。如果需要深入阅读,Amit Patel的网站是最佳来源之一。
规划
我们通过寻路发现,有时选一个方向再笔直地移动过去是远远不够的,往往需要转几个弯才能到达目的地。我们可以把这个思想概括为各种各样的概念,目标不是仅靠下一步就能实现的,而是需要一系列的步骤,你可能需要推演好几步才能知道第一步怎么走。这就是我们所说的规划(planning)。寻路可以被认为是规划的一种特定应用,但是规划这个概念还有更多的应用。就我们的”感知/思考/行动“循环而言,规划就处在”思考“阶段规划未来多个行动的时候。
让我们看一下《万智牌(Magic: The Gathering)》游戏。在第一回合,你有一些手牌,包括一张提供1点黑色法术力的沼泽,一张提供1点绿色法术力的树林,一张需要1点蓝色法术力来召唤的漂泊法术师(Fugitive Wizard)和一张需要1点绿色法术力才能召唤的妖精秘教徒(Elvish Mystic)。(为了简单起见,我们先忽略其他3张牌。)大致规则是:玩家每回合可以使用(打出)1张地牌,可以“横置(Tap)”地牌来产生法术力。如果有足够法术力的话,施放尽可能多的法术(包括召唤生物)。在这种情况下,人类玩家应该会先使用(打出)森林地牌,横置它来产生1点绿色法术力,然后再召唤妖精秘教徒。但是游戏AI如何知道做出这样的决策呢?
简单”规划器“
最简单的方法或许就是:依次尝试每个动作,直到没有合适的动作为止。看看自己的手牌,看到可以打出沼泽,就打出这张牌。然后这回合还有其他动作可做吗?不能召唤妖精秘教徒也不能召唤漂泊法术师,因为它们分别需要绿色和蓝色法术力,而我们在场的沼泽只能提供黑色法术力。我们不能再打出森林地牌,因为我们已经打出了沼泽。所以虽然AI玩家完成了一个有效的回合,但不是一个非常理想的回合。幸运的是,我们可以做得更好。
寻路算法通过搜索得到一个位置的列表,并依此穿越世界最终达到期望位置。与寻路的方法类似,我们的规划器也可以找到一个动作列表,使游戏进入期望状态。路径上的每个位置都有一组邻居,它们是路径上下一步的潜在选择。与此类似,计划中的每个动作都有邻居或“继任者”,它们是计划中下一步的候选对象。我们可以搜索这些动作以及后续动作,直到达到所需状态为止。
在示例中,假设期望的结果是“尽可能召唤一个生物”。回合开始时,我们只能根据游戏规则允许2种潜在动作:
1. 使用(打出)沼泽地牌(结果:沼泽从手牌中移除,进入战场)
2. 使用(打出)树林地牌(结果:树林从手牌中移除,进入战场)
还是取决于游戏规则,所采取的每个动作会启用一些动作,禁用其他一些动作。假设我们选择使用沼泽地牌,那么会将该动作从继任动作中排除(因为已经使用过沼泽),因此将“使用树林地牌”也删除了(因为游戏规则允许每回合只能使用一张地牌),并添加“横置沼泽地牌以获得1点黑色法术力”作为继任动作——实际上也是唯一的继任者。如果我们再进一步选择“横置沼泽地牌”,我们将会获得1点无法使用的黑色法术力,这毫无意义。
1. 使用(打出)沼泽地牌(结果:沼泽从手牌中移除,进入战场)
1.1 横置沼泽地牌(结果:沼泽被横置,+1 黑色法术力)
没有可用动作 - 结束
2. 使用(打出)树林地牌(结果:树林从手牌中移除,进入战场)
这些简短的动作并没有取得多大成就,如果我们用寻路做类比的话,那么我们将陷入僵局。因此,我们重复执行下一个动作的过程。我们选择“使用(打出)树林地牌”,同样地,将“使用(打出)树林地牌”和“使用(打出)沼泽地牌”从候选项中移除,并打开“横置树林地牌”作为下一步(也是唯一的步骤)。这给了我们1点绿色法术力,在这种情况下,它打开了第三步,即召唤妖精秘教徒。
1. 使用(打出)沼泽地牌(结果:沼泽从手牌中移除,进入战场)
1.1 横置沼泽地牌(结果:沼泽被横置,+1 黑色法术力)
没有可用动作 - 结束
2. 使用(打出)树林地牌(结果:树林从手牌中移除,进入战场)
2.1 横置树林地牌(结果:树林被横置,+1 绿色法术力)
2.1.1 召唤妖精秘教徒(结果:妖精秘教徒进入战场,-1 绿色法术力)
没有可用动作 - 结束
现在我们探索了所有可能的动作以及这些动作之后的动作,并且找到了一个计划,使我们可以召唤生物:使用(打出)树林地牌,横置树林,召唤妖精秘教徒。
显然这是一个非常简单的示例,一般你会希望选择最佳计划,而不是仅选择满足某种条件(例如“召唤生物”)的计划。通常来说,你可以根据最终结果或遵循该计划的累积收益来对潜在计划进行评分。比如,你可能会因使用地牌而获得1分,并因召唤生物而获得3分。“使用(打出)沼泽地牌”是一个简短的计划,可得1分,但是“使用树林地牌 → 横置树林 → 召唤妖精秘教徒”是一个可得4分的计划,其中土地1点,生物3点。这将是获得最高评分的计划,因此它会被选中并执行。
我们已经展示了如何在万智牌的单个回合中完成规划,但是也可以应用于连续的回合中规划(例如在国际象棋里,先移动兵从而为主教的出子腾出空间。或者在 XCOM 里冲刺到掩体里,以便下一回合从这里射击),也可以随着时间的推移采取总体策略(例如,在星际争霸里,建造其他神族建筑之前先建造水晶塔,或者在上古卷轴:天际里,攻击敌人之前猛喝强化生命药水)。
改进型规划
有时每一步会有太多的候选动作,以至于我们无法合理考虑每个排列。回到万智牌的例子,假设我们手中有几张生物牌,战场上也有足够多的地牌,那么我们就可以召唤其中之一,还有战场上具有某些能力的生物,还有几张尚在手中的地牌——使用地牌,横置地牌,召唤生物,还有使用生物异能等等,这些动作的排列组合方式能达到数千甚至上万!幸运的是,有两种方法可以解决这个问题。
第一种方法是“后向链接”。与其尝试所有动作并检查其结果,不如从我们想要的最终结果开始,看看是否可以找到一条直达路线。打个比方,想办法从树的树干到达特定的叶子,但从叶子向后处理更有意义,这样可以轻松地追踪到树干的路线(然后再反过来),而不是以树干为起点,每一步猜测要走哪个分支。通过从结尾开始然后反向进行,可以更快更轻松地作出规划。
例如,如果对手的生命点数为1,则找到“对对手造成1点以上的直接伤害”的计划可能会很有用。为此,我们的系统知道它需要施放直接伤害法术,反向意味着系统必须有一个法术手牌并且有足够的法术力来施放它,这又反向意味着系统必须能够横置足够的地牌来获得该法力值,这又导致它可能需要打出一张额外的地牌。
另一种方法是“最佳优先搜索(Best-First-Search)”。我们没有详尽地遍历动作的所有排列,而是衡量每个局部计划的“良好”程度(类似于我们在上述计划之间进行选择的方式),并且每次评估出看上去最好的一个。通常我们能够规划出一个最佳计划,或者至少是足够好的计划,而无需考虑计划的所有可能变更。A* 是最佳优先搜索的一种形式,通过首先探索最有希望的路线,它可以找到通往目的地的路径,而无需在其他方向上进行过多的探索。
最佳优先搜索中一个有趣且日益流行的变体是蒙特卡洛树搜索(Monte Carlo Tree Search, MTCS)。在连续的动作决策过程中,它不会去猜测哪个计划比其他计划更好,而是每一步选择随机的后续动作,直到没有更多动作可用时结束(可能是假设的计划达成了游戏的胜利/失败条件),并且该结果来衡量先前选择的优劣。通过连续多次重复这个过程,即使情况发生变化(比如对手采取预防措施来阻止我们),也可以很好地估算出哪个下一步最好。
最后,如果不提及“面向目标的行动规划(Goal-Oriented Action Planning, GOAP)”(简称GOAP),那么关于游戏AI规划的讨论就不算完整。这是一种广泛使用和讨论的技术,但是除了一些特定的实现细节外,它本质上是一个后向推理规划器。先从目标开始,然后选择实现目标的行动,或可以实现目标的一系列行动。例如:如果目标是“干掉玩家”,而玩家处于掩护状态,则计划可能是 “投掷手榴弹(FlushOutWithGrenade)” → “拔出武器(Draw Weapon)” → “攻击(Attack)”。
通常我们会设计几个目标,每个目标都有其自己的优先级。如果不能满足最高优先级的目标(例如,由于看不见玩家,则无法用行动组成“杀死玩家”计划),它会回退到优先级较低的目标,比如“巡逻”或者“站岗”。