游戏AI入门指南(Part 1)
原文: The Total Beginner’s Guide to Game AI 作者: Ben Sizer 译者: Anthony Han
这是一篇非常好的综述类文章,对当今的游戏AI常用技术和实现方法做了简单介绍,参考了近年来的 Game AI Pro 系列。虽然不及论文那样严谨,但全文条理清晰,通俗易懂。确实是一篇入门指南佳作。花了点业余时间翻译出来,为了分享,也希望能温故知新。
引言
本文将介绍游戏人工智能(或简称“游戏AI”)的入门概念,让读者了解使用哪些方法来处理AI问题,它们如何协同工作以及如何使用相应的语言或引擎来实现。
我们假设你具备电子游戏的基本知识,并掌握几何,三角函数等数学概念。大多数代码示例为伪代码,因此不需要特定的编程语言知识。
什么是游戏AI?
游戏AI主要关注实体根据当前条件所采取的行动。这就是传统人工智能文献所指的控制“智能代理”,代理通常是游戏中的角色,但也可以是车辆,机器人。或者更抽象的东西,例如一组实体,甚至一个国家或文明。智能代理需要在各种情况下观察周围环境,依此做出决策,并采取行动。这就是所谓的“感知/思考/行动(Sense/Think/Act)”循环:
- 感知:代理侦测到或被告知环境中可能影响其行为的事物(例如:附近的威胁,要收集的物品,要调查的兴趣点)。
- 思考:代理决定采取的应对措施(例如:考虑是否足够安全来收集物品,或者决定应该先集中精力战斗还是躲藏)。
- 行动:代理将先前的决定付诸行动(例如:沿着通向敌人或物品等的路径移动)。由于代理做出了行动,形势已经改变,因此再次重复循环。
现实世界中的AI,特别是成为新闻热点的那些,通常主要关注循环中的“感知”部分。例如,自动驾驶汽车拍摄道路的图像,结合其他数据(例如雷达和光达),并分析所看到的状况。这个过程一般是通过机器学习来完成,机器学习尤其擅长这方面,获取大量现实世界中有噪声的数据(如汽车前方的道路照片或视频)并加以分析理解,提取诸如“前方20码处有一辆汽车”这类的语义信息。这些被称为“分类问题”。
游戏的不同之处在于,它不需要复杂的系统来提取信息,因为大部分游戏的本质就是模拟。如果前方有敌人,也无需用图像识别算法来识别;游戏知道那里有敌人,可以将这些信息直接输入到决策过程。因此“感知/思考/行动“循环的“感知”部分通常要简单得多,但“思考”和“行动”的复杂性也会显现出来。
游戏AI开发的限制
游戏AI通常会遵从一些限制条件:
- 它不像机器学习算法那样被“预训练”:在开发过程中编写神经网络,对大量玩家进行观察并学习找到与之对抗的最佳方法。这种做法是不切实际的,因为游戏还没有发售,并没有玩家!
- 游戏应该提供娱乐性和挑战性,而不是“最优解”。所以即使AI被训练成完美机器,可以采用最佳方式对抗人类,这也不符合游戏设计师的初衷。
- 代理需要显得“真实”,这样玩家才能觉得自己在与类似人类的对手对抗。AlphaGo的表现远超人类,但它的落子策略也远远超出了人类对围棋的理解,以至于它的人类对手会觉得“自己像是在和外星人下棋”。如果游戏AI的目的是成为人类的对手,恐怕这样的游戏是不太受欢迎的。因此必须对算法进行调整以做出可信的决策,而不是理想的决定。
- 游戏AI需要“实时”运行——这就意味着AI算法不能有太高的CPU占用。即使10毫秒也太长了,因为大多数游戏只有16到33毫秒的时间来执行下一帧图形的所有处理过程。
- 如果游戏中有些系统是数据驱动而不是硬编码的,这是非常不错的设计,非编码人员可以更快地调整设置。
记住这些要点,我们就可以去了解一些非常简单的AI实现方法。这些方法可以高效地完成整个“感知/思考/行动(Sense/Think/Act)” 循环,让游戏设计师设计出具有挑战性和类似人类的AI行为。
基本决策
让我们从一个非常简单的游戏开始,例如乓(Pong)。玩家的目标是移动“球拍”,接住球并让球从球拍上反弹,规则就像网球一样,当你没有回球时就算输球。AI的任务比较简单,就是确定朝哪个方向移动球拍。
硬编码的条件语句
要编写一个控制球拍的AI,有一个直观又简单的解决方案——只要始终将球拍放在球的下方即可。当球接近球拍时,如果球拍已经完美就位,那么就可以把球弹回。
如果用“伪代码”描述,那么这个简单的算法可能如下所示:
游戏运行时的每帧Update:
if 球在球拍的左边:
左移球拍
else if 球在球拍的右边:
右移球拍
假设球拍可以像球一样快速移动,那么对于Pong的AI玩家来说,这应该是一个完美的算法。如果没有其他可用的感知数据,也没有太多的动作可以执行,那么你就不需要更复杂的算法。
这种方法非常简单,几乎看不到整个“感知/思考/行动”循环。但它确实存在。
- “感知”部分在2个“if”语句中。游戏知道球和球拍的位置。所以当AI向游戏查询这些位置时,就“感知”到球是向左还是向右。
- “思考”部分也在2个“if”语句中。这两个互斥的语句会使AI执行以下三个动作之一:将球拍向左移动,向右移动,或者不动。
- “行动”部分是“左移球拍”和“右移球拍”语句。根据游戏不同的实现方式,可能会立即改变球拍位置,或者在代码里设置球拍的速度和方向,使其正确地移到的其他位置。
这样的方法通常被称为“反应型(Reactive)”,因为一组简单的规则(本例中为代码里的“if”语句),它会对当前世界状态做出反应并立即决定如何采取行动。
决策树
上面的Pong示例其实等效于叫做“决策树”的AI概念。在这个系统中,决策被排列成树形,通过算法遍历才能到达“叶子”——采取动作的最终决策。我们可以用流程图来直观表示Pong球拍的决策树:
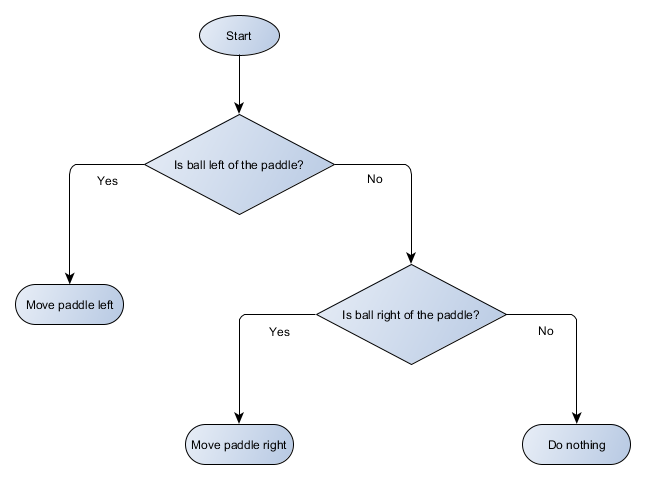
它像一棵倒立的树!
AI使用图来描述这种结构,决策树的每个部分称为“节点”,节点有以下两种类型:
- 决策节点:通过检查某些条件,在两个备选方案之间进行选择,方案也用节点表示;
- 结束节点:要采取的行动,代表决策树做出的最终决定。
从指定为树“根”的第一个节点开始,根据决策节点中的条件决定要移动到某个子节点,或者执行存储在该节点中的动作并停止。
乍看上去,似乎决策树的优点并不明显,它显然在做上一节中if语句相同的事。但决策树是一个非常通用的系统,每个决策包含1个条件和2个可能的结果,开发人员可以用决策数据构建AI,而无需硬编码。我们可以很容易地用简单的数据格式来描述决策树:
| 节点编号 | 决策 (或者 “结束”) | 动作 | 动作 |
|---|---|---|---|
| 1 | 球在球拍的左边? | 是?检查节点2 | 否?检查节点3 |
| 2 | 结束 | 向左移动球拍 | 向左移动球拍 |
| 3 | 球在球拍的右边? | 是?转到节点4 | 否?转到节点5 |
| 4 | 结束 | 向右移动球拍 | 向右移动球拍 |
| 5 | 结束 | 什么也不做 | 什么也不做 |
在编码时,你需要构建一个系统来读取表数据,为每行创建一个节点,根据第2列的节点类型来连接决策逻辑,根据第3列和第4列来连接子节点。虽然仍要对条件和动作进行硬编码,但现在设想有一个更复杂的游戏,你可以添加更多的决策和动作,并可以通过编辑带有树定义的文本文件来配置整个AI。将文件交给游戏设计师,他们可以调整行为而无需重新编译游戏和更改代码——前提是你已经在代码中预制了要用的条件和动作。
决策树真正强大的地方在于可以基于大量示例(例如使用ID3算法)自动构建决策树。这使它成为一个用来通过输入数据对情况进行分类的有效且高性能的工具。但这超出了代理选择行动的设计师编写的(designer-authored)简单系统范畴。
脚本
前面我们设计了一个决策树系统,它可以利用预先编写的条件和动作。AI的设计者可以按自己的意愿排列树的结构,但他非常依赖程序员预先设置好的条件和动作。如果我们可以为设计师提供更好的工具,让他们能够自己创建某些条件,甚至某些行为,如何才能做到呢?
打个比方,只要提供一个这样的系统:设计师自己编写条件来判断数值,而不必由程序员为 “球在球拍的左边?”和“球在球拍的左边?”编写代码。决策树的数据可能最终像这样:
| 节点编号 | 决策 (或者 “结束”) | 动作 | 动作 |
|---|---|---|---|
| 1 | ball.position.x < paddle.position.x | 是?检查节点2 | 否?检查节点3 |
| 2 | 结束 | 向左移动球拍 | 向左移动球拍 |
| 3 | ball.position.x > paddle.position.x | 是?转到节点4 | 否?转到节点5 |
| 4 | 结束 | 向右移动球拍 | 向右移动球拍 |
| 5 | 结束 | 什么也不做 | 什么也不做 |
与前面的决策树类似,但是决策中包含代码,看起来有点像if语句的条件部分。在编码时,需要读入第2列的“决策”节点,而不是查找要运行的特定条件(例如“球在球拍的左边?”),评估条件表达式并相应地返回true或false 。这可以通过嵌入脚本语言来完成(例如 Lua 或 Angelscript),它允许开发人员在游戏中获取对象(例如,球和球拍)并创建可以在脚本中访问的变量(例如,“ball.position”)。脚本语言通常比 C++ 更容易编写,而且不需要通过编译,因此它非常适合快速调整游戏逻辑,只要少量人员来设计功能而无需程序员的干预。
在上面的示例中,脚本语言仅用于评估条件表达式,但是没有理由不用来处理输出动作。例如,动作数据(如“向右移动球拍”)可以变成脚本语句(如"ball.position.x + = 10"),因此动作也可以在脚本中定义,而无需程序员硬编码 MovePaddleRight 函数。
更进一步,我们可以用脚本语言编写整个决策树,而不是使用一行行的数据表。类似于我们前面介绍的硬编码条件语句代码,但不对其“硬编码”——它保存在外部脚本文件里。这意味着我们可以在不重新编译整个程序的情况下修改决策树,甚至可以在游戏运行时更改脚本,从而允许开发人员快速测试不同的AI方法。
响应事件
上面的示例都是在Pong这样的简单游戏中每一帧运行的。思路就是可以连续运行“感知/思考/行动(Sense/Think/Act)”循环,并根据最新的世界状态继续行动。但对于更复杂的游戏,与其评估所有内容,不如对“事件”做出响应更为有意义,这些事件就是游戏环境中的显著变化。
这种方法不适用于Pong,所以我们选择一个不同的示例。假设有这么一个射击游戏:敌人一直处于静止状态,直到他们侦测到玩家,然后他们根据其身份采取不同的行动——格斗士可能会向玩家冲锋,而狙击手会后退并瞄准。本质上讲,这仍然是一个基础的反应型AI系统——“如果看到玩家,那就做某事”——但从逻辑上讲,它可以分为事件(“看到玩家”)和反应(选择一个行动并执行)。
这让我们又回到了“感知/思考/行动(Sense/Think/Act)”循环。我们可能会用一些代码——即“感知”代码——在每帧检查敌人是否可以看到玩家。如果为否,则什么也不做。但如果为是,则会创建“玩家可见”事件。代码中将有一个单独的部分用来处理,例如“发生‘发现玩家事件’时,执行xyz”,而xyz就是处理思考和行动的响应。对于格斗士角色,你可以将“ChargeAndAttack”响应函数连接到“发现玩家”事件;对于狙击手角色,你可以将“HideAndSnipe”响应函数连接到该事件。与前面的示例一样,你可以在数据文件中进行关联,以便快速修改而无需重建引擎。而且还可以(通常如此)用脚本语言编写这些响应函数,以便设计师可以在发生这些事件时做出复杂的决定。