《光环 2》的游戏AI系统设计
Conference: GDC 2005
Speaker(s) : Damian Isla
Video: Managing Complexity in the Halo 2 AI System - YouTube
《光环》系列的 AI 久负盛名,其行为树的应用堪称业界典范。而 Damian Isla 在 GDC 2005 的演讲《Managing Complexity in the Halo 2 AI System》成了行为树架构设计绕不开的参考资料。结合演讲视频和演示幻灯片,精读了文章《GDC 2005 Proceeding: Handling Complexity in the Halo 2 AI》。
复杂性问题
可扩展性的复杂性
可扩展性(Scalability)的3个维度:
- Variety: 大量不同的角色:野猪兽,精英,鬼面兽,猎人,地狱伞兵,海军陆战队……
- Variation: 不同的使用故事场景:叙事性,节奏性,戏剧性,挑战性……
- Volume: 大量不同的行为:近战,射击,驾驶,躲藏……
设计需求的复杂性
- Transparency:即使是不了解 AI 内部工作原理的外行观察者(玩家)能够对AI的内部状态做出合理的推断,并以此来解释和预测AI的行为。
- Coherence:保持行为的连贯性和一致性。为了让AI的行为更连贯自然,需要注意启动、停止动作的时机合理。还要特别防止 AI 行为中出现摇摆不定问题,即在两个选项间反复切换的现象。
- Directability:保证可指挥性,AI 系统应该能够接受设计师的指示和命令。
- Workability:对设计和开发它的工程师应该要有足够的可操作性,工程师需要能够读取、理解AI系统内部的状态和运作机制,对 AI 系统进行测试、调试、修改与优化。
如何管理复杂性
决策机制
行为 DAG
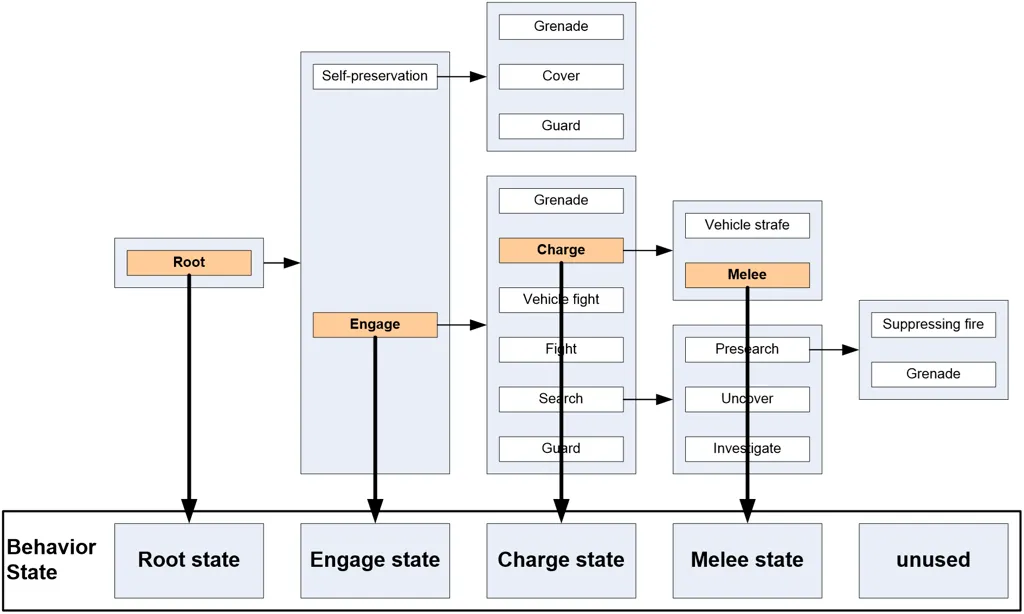
Halo 2 AI实现了行为树,更具体地说,是行为DAG(有向无环图),因为单个行为(或行为子树)可以占据图中的多个位置。下图为Halo 2的实际核心行为DAG的精简版本,原图包含50种不同的行为。
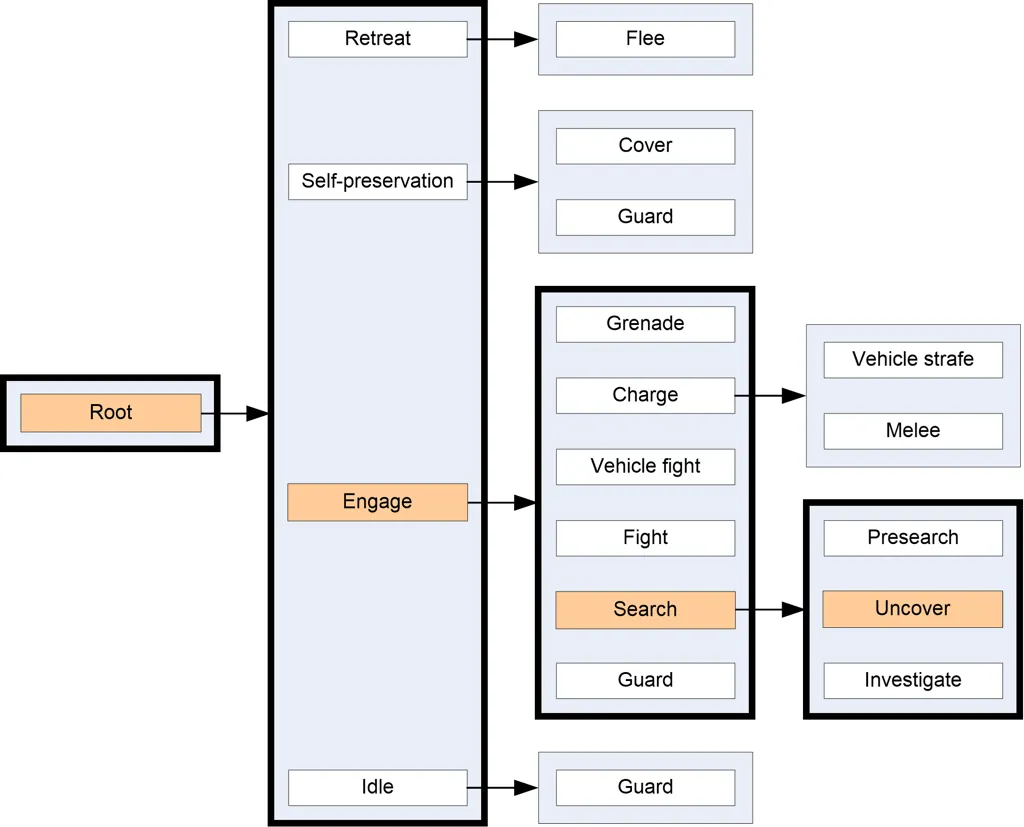
优点:
- 直观明了
- 模块化
- 易扩展
缺点:
- 实现不算简单
- 调试困难
- 数据存储困难
决策方式
在典型的层次状态机(HFSM)中,非叶节点行为的角色是做决策(即选择哪个子节点来运行),而叶节点行为的角色是完成实际的任务。
关于非叶节点的决策方式,有两种一般方法:
(a) 父节点使用自定义代码进行决策 (b) 子节点之间竞争,父节点根据子节点的运行意愿(desire-to-run)值或相关度进行决策
在不同情况下这两种方式都有用,所以留下了自定义决策逻辑的可能性。
子节点竞争
由于战斗逻辑循环的一些核心组件,每个组件很多子节点(大约10到20个),如使用父节点自定义的方式硬编码,则不利于扩展和维护。
决策模型
- analog relevancy
- binary relevancy
Analog Relevancy
许多系统使用模拟激活意愿(analog activation desire),每个子行为给出一个0-1的浮点数表示其相关性,选择相关性最高的子行为作为胜者(并且会给上一帧的胜者一个加分以避免行为摇摆的问题)。
但是,当竞争的行为数量很多时,这种方式会面临可扩展性问题,特别是当希望定义非常具体的优先级时(比如“攻击目标,除非玩家驾驶载具过来,那时候进入玩家载具”)。调整浮点数来得到具体的规则或优先级,在只有2-3个选项时可行,但当有20多个选项时几乎不可能。1
Binary Relevancy
为了解决这个问题,Halo 2 使用了一种简化的二值相关性方法。每个子行为只返回一个bool值指示其当前是否关联。这种方式在有大量子行为时定义优先级更简单直接,因此文章中使用了这种binary relevance的方式。
- 优先列表(prioritized-list): 按优先级顺序检查子节点,第一个可以运行的节点被选中,但更高优先级的节点可以中断当前运行的节点。
- 顺序检查(sequential): 按顺序运行子节点,并跳过不相关的节点。当运行到列表结尾时,父节点执行完毕。
- 循环顺序检查(sequential-looping): 与序列相同,但执行到列表结尾时,重新开始。
- 概率选择(probabilistic): 从相关子节点中随机选择。
- 单次选择(one-off): 以随机或优先的方式选择一个子节点,但从不会重复同样的选择。
其中最常用的是优先列表,它最贴近人类解决问题的思维方式。使用这些预定义的简单判断,就可以避免手动编码复杂的判断逻辑,提高行为树的可扩展性和可维护性。
设计原则1:一切都可以自定义,支持多种设计
Behavior Impulses
Binary Relevancy 可以解决很多问题,但也带来一个新问题:如果优先顺序不是固定的,应该如何处理?例如,在某些情况下,行为A优先于行为B(“战斗而不是进入附近的车辆”),但在其他情况下,行为B优先于行为A?(“除非玩家在车辆中,否则在这种情况下一定要上车。”)
为了解决这个问题,Halo 2 使用了行为冲动(Impulse)。冲动是一个自由浮动的触发器,就像完整的行为一样,它提供了 Binary Relevancy,但它本身只是对完整行为的引用。当冲动赢得竞争时,它有两种执行方式:
- In-Place:引用行为在冲动的位置运行
- Redirect:将当前运行的行为堆栈重定向到引用行为的位置
In-Place
在上面的例子采用 In-Place 就地执行的方式。因此优先级列表变成了
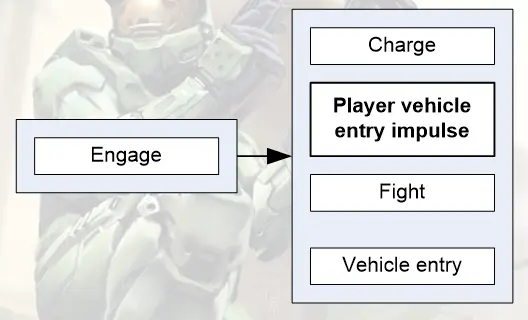
在执行完冲动引用的行为后,可以继续执行“战斗”行为。
Redirect
“冲动”还可以将当前运行的行为堆栈重定向到引用行为的位置。例如,在“进攻”行为节点下会设置一些自我保护冲动(因受伤而寻求自保,因面临强敌而寻求自保……),因此如果在执行进攻时选择了自我保护节点。那么可以弹出行为执行堆栈的节点,重定向到“自我保护”节点。而不是在“进攻”节点下执行“自我保护”。冲动相当于充当了指向其它分支的“指针”,并将当前的执行节点跳转到该分支。

设计原则 2:明确性高于一切,形式化复杂性,不要隐藏它。
Hacks
“冲动”还能够以另一种方式发挥作用。假设有一个永远不返回正面相关性的“冲动”,它不会触发任何行为的运行。但它本身是一个任意的、轻量级的代码片段,可以在行为 DAG (有向无环图)的特定位置运行。我们可以用它来做什么呢?任何事情。例如:
- 调用日志函数,记录到达优先级列表中的某点。
- 输出一些调试信息到控制台
- 在满足某条件时,使角色发出声音
这段代码不需要明确地作为一个行为的一部分来做有用的事情。这个做法可能会被认为是一种 hack 手段,因为它跳过了执行行为这个必要步骤。但事实上,这正是“冲动”构造的设计目的之一:提供一种方便的方式,在行为 DAG 的特定位置加入任意代码片段。
设计原则 3:拥抱 Hack 手段,允许变通,不要墨守成规。
Behavior Tagging
问题: 随着树逐渐变大,行为的相关性检查成为了运行时性能的一大负担。因为经常检查许多没有实际运行的行为和冲动的相关性。而且许多候选行为的条件是相同的。例如,在计算相关性时几乎总是检查车辆状态( Actor 是司机、乘客还是步行)和警觉状态(AI 是否与看见目标,还是觉察到目标,还是没发现任何目标)。
为了解决这个问题,行为标签的方法应运而生。我们把常用的条件移除相关性检查函数,从而避免了反复编写同样的条件。Halo 2 中,这些常用条件被编码到一个bitvector里,然后与 AI 当前状态的bitvector进行比较。只有条件满足的行为和“冲动”才会进行全面的相关性检查,否则会被忽略。
行为标签可以被视为加速相关性检查的一种方式,但还有另一种有趣的解释。我们可以将这些条件视为锁定和解锁行为树的大部分内容,从而修改其基本结构。例如,对于车辆的乘客来说,行为树中解锁的部分非常有限:例如,控制逃跑、自保和搜索等主要分支对其来说是不可用的。车辆驾驶员可以使用更多的内容,但仍然不及步兵 AI 。如果我们仔细观察交战行为,我们会发现另一件事情:驾驶员和步兵单位的战斗行为是不同的,步兵单位使用的是fight_behavior,而驾驶员使用更专业化的vehicle_fight_behavior(后者使 AI 保持不断移动,而前者则倾向于选择位置并停留在那里)。同样,对于驾驶员与步兵单位而言,搜索过程也大不相同,主要是因为步兵单位在此过程中具有一系列协调行为,使得搜索成为一项团队活动。
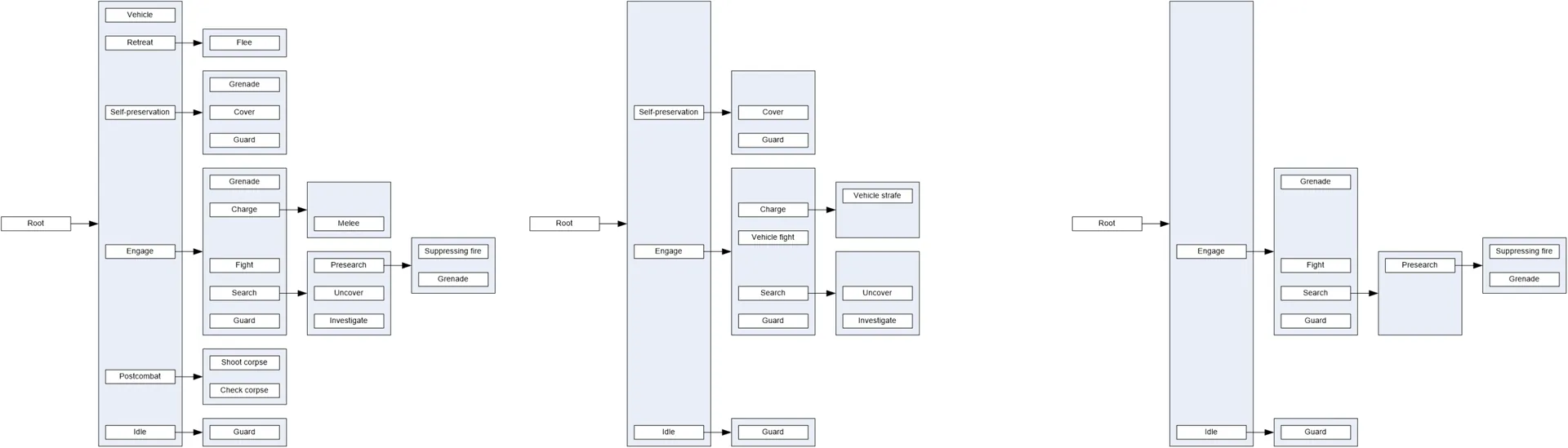
Stimulus Behaviors
问题: 在行为树每次更新时,很少触发的事件驱动行为也会检查。在一定程度上引起了不必要的性能消耗。
例如,野猪兽有一个“在首领被击杀之后逃跑”的冲动,这个冲动要等到“Actor 死亡”事件发生时才开始执行,先检查死掉的 Actor 是否为首领,附件是否有其他首领等等。如果满足所有条件,则触发逃跑行为。但是基于目前的 AI 架构,这个冲动会在每次更新时进行条件检查,即使没有“Actor 死亡”事件发生。为了避免这种频繁检查的问题,我们希望让这种冲动变成“事件驱动”的。
因此引入了 刺激行为(Stimulus Behavior) ,它本质上是一种行为或冲动,它不会出现在静态树结构中,而是由事件处理函数动态添加到树上的特殊节点。在上述的示例中, Actor 在其主循环异步接收 “Actor 死亡” 事件(事件通知通过回调函数实现),如果死亡的 Actor 属于首领,导致flee_because_leader_died 刺激冲动被添加到接收事件的 Actor 行为树中。这意味着在给定的时间段内(Halo 2 中为1-2秒),该冲动将与所有其他静态行为和冲动一起被考虑执行。

为什么要将冲动放入行为树中?如果从某种意义上说,除非行为是在整个行为树的背景下做出的,否则它不会是一个经过深思熟虑的决定。在上面的例子中,如果我们已经在运行 enter_player_vehicle,我们不会去考虑逃跑,但如果我们只是运行 engage,我们可以考虑逃跑。在事件处理函数中检查这些条件是极其荒唐的,更不必说高度不可扩展了。只有将刺激行为放入行为树整体中,我们才能确信,在刺激行为执行之前,所有更高层和更优先的行为都有参与执行的机会。
Custom Behaviors
问题: 不同类型的角色有不同的特定行为:只有一种类型角色执行的行为,不必所有类型的角色都去评估。例如,野猪兽的 retreat from scary enemy 冲动。
在某些情况下,我们只需调整行为参数以达到所需的效果。在其他需要更具体触发器的情况下,我们将使用 自定义行为(Custom Behavior) 。与刺激行为类似,自定义行为也会插入到树中,但它是预先处理的而不是运行时动态加入的,这样最终的优先级子列表就不需要每次重新计算。通过这种方式,我们可以添加任意数量的角色特定冲动、行为或行为子树。通过添加这些节点,角色的很多个性都能体现出来(Halo 2中胆小的野猪兽具有很多的撤退冲动,而陆战队员则具有额外的行动协调行为,从而实现多单位协作)。
设计原则 4:在一个稳定的基础上进行变化。
当然了,如果需要一个真正完全不同的 AI,那么从同一个基础开始有些不切实际。Halo 2 中洪魔的基本需求与普通角色完全不同,因此它们有一个完全自定义的行为 DAG。
Joint Behaviors
问题: 多单位的协调行为如何处理?例如,几个陆战队的队员如何针对类似或相同的目标,进行分工协作或者配合?
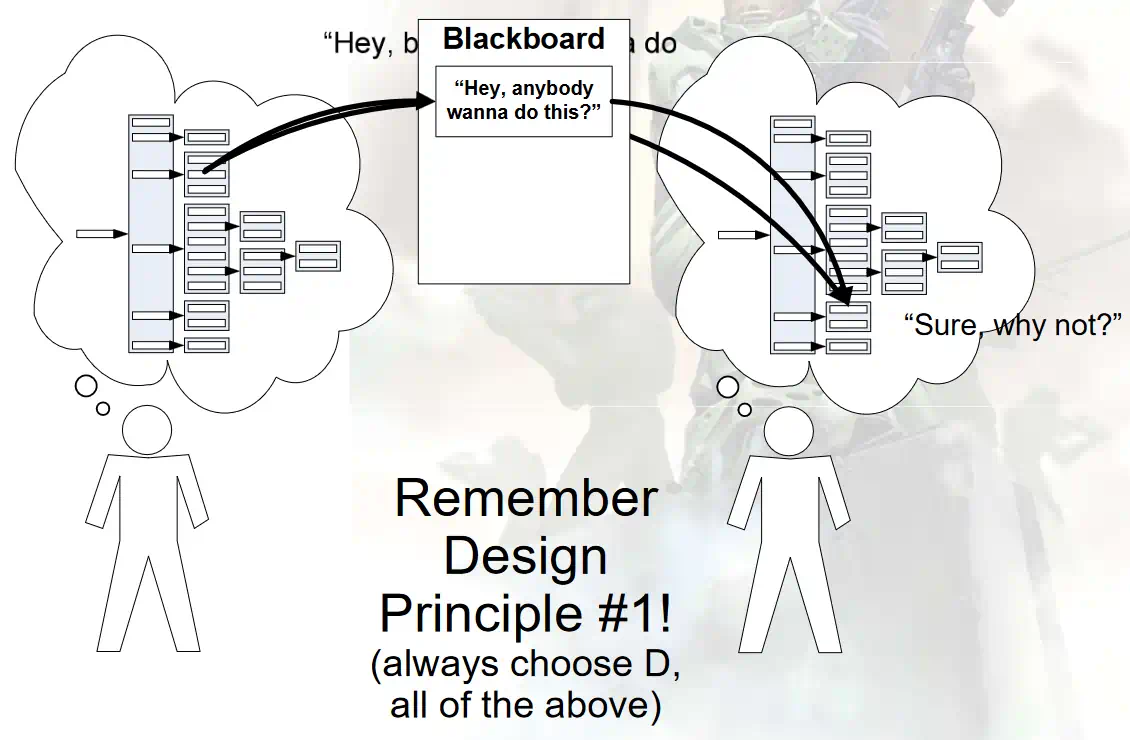
使用 联合行为(Joint Behavior) 解决这个问题。Actor 会在特定情况下,发送邀请给其他 Actor,邀请他们共同完成某项任务。如果其他 Actor 同意,便会一起协调,共同完成某项任务。
例如,游戏中常见的载具翻车问题,当三人乘坐的疣猪号翻车时,会使用联合行为,乘员一起下车并站在载具的同一侧,将载具翻转之后,再一起上车。
另一种可行办法则是使用 黑板(Blackboard) ,这种方法相当于 Actor 广播一条长期的邀请,希望愿意加入的 Actor 随时加入。
Memory and Memory
内存
对于大型的行为树,每个 AI 都需要分配一棵完整的树,每个行为都需要持久化存储来保存其状态,这样行为所需的状态就可以一直可用。但如果同时有100个 Actor,每个行为树平均有60个行为节点,每个节点占32字节内存。这就需要大约192KB的持久化行为存储空间。随着行为树规模的增长,这种存储需求会成为非常大的内存负担,特别是对于像 Xbox 这样的平台。
一个显而易见的优化是为每个 Actor 创建一个小型状态内存池,该池被划分为与行为树层级相对应的块。树由此变成了一个独立的静态结构(即不是为每个 Actor 分配的),行为本身成为对块进行操作的代码片段。如果父行为对象仅在选择子对象时实例化其子对象,则可以以面向对象的方式获得相同类型的内存使用量。这是 “The Suffering: A Game AI Case Study”2 中采用的方法。我们的内存使用变得更有效率:100 个 Actor * 64 字节(所需行为存储量的上限)* 4 层(以 Halo 2 的情况),大约 25KB。非常重要的是,这个数字只随着树的最大深度而增长,而不是随着行为的数量而增长。
然而,这样带来了另一个问题,持久化 行为状态的问题。在 Halo 2 中,有许多在最后一次成功执行(例如投掷手榴弹)后的一段时间内不允许再执行的行为。在理想情况下,有关“上次执行时间”的信息将存储在持久分配的手榴弹行为中。但由于上述方案中的存储只是临时分配的,因此我们需要在其他地方存储持久性行为数据。
还有一个更糟糕的例子:与每个目标相关的持久化行为状态如何处理?比如搜索行为。搜索行为希望在它对某个特定目标的操作失败时进行指示。这可以让 Actor 知道忘记这个目标,将精力集中到其它地方。但这并不排除 Actor 去寻找其它 不同 的目标,所以不能仅仅因为搜索失败就关闭这个行为。
记忆
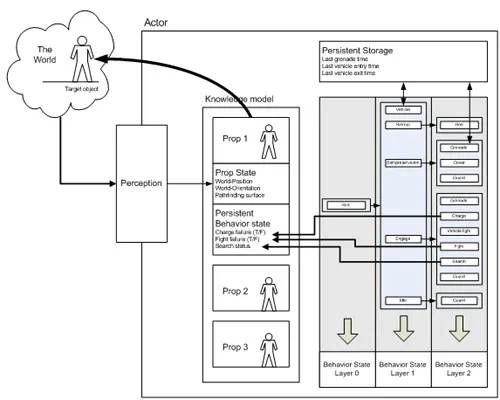
记忆,在心理学上指过去行为和事件的存储信息,而不是RAM的意义上。记忆是树结构固有的问题。解决方案是创建一个或多个记忆池,在树外充当其存储代理。
我们可以将记忆分为四个不同的类别:
- 每个行为的持久记忆:投掷手榴弹、最近的车辆相关行动
- 每个行为的短期记忆:行为完成时就丢弃的状态
- 每个对象的记忆:感知信息,上次发现的位置,上次发现的朝向
- 每个对象每个行为的记忆:上次交战时间,搜索失败信息,寻路失败信息
第一种类型是最简单的,我们可以直接在 Actor 对象中定义变量,特定的行为能够读写这些变量。持久状态的行为数量最好保持在最低限度,并且其对应的状态最好保持最少。
第二种类型是我们一直在讨论的类型。这是在特定行为开始时分配,停止时释放的易失性状态。
第三种和第四种记忆类型使问题变得更加复杂。它们表明角色评估的每个目标都需要角色内部的参考表示。拥有这样的表示具有许多好处。
感知方面的优点已经在 Burke013 和 Gresimer024 中做了详细的讨论。在Halo 2中,这些表示称为“props”,其主要功能是作为游戏世界里物体感知信息的存储库。将这些状态信息(位置、方向、寻路位置等)与实际的世界状态分开,并由角色的感知过滤器进行控制(例如,角色不应该能够穿墙看见),让这两个表示偶尔出现差异,让角色感知的事情并不都是真实的,从而我们现在进入了可以欺骗、混淆、惊讶、失望等的人工智能领域。
这里的新意在于,prop 还可以作为每个物体的每个行为状态的存储位置。将这种行为状态与感知历史存储在同一位置也使我们能够方便地将两者进行相关性分析,从而使我们能够有效地回答类似“我是否已经搜索过我听到的敌人?”的问题。与以往一样,保持每个对象持久存储的行为越少越好,并且这种存储需要保持小巧。

“prop” 表示是 Halo 2 AI 的基石之一,基本上构成了 AI 对其周围世界的观察和理解的全部 知识模型(knowledge model) 。不幸的是,这个模型仍然非常基础。毕竟它只是一个对象引用的平面列表,没有空间关系(相邻或上方),也没有结构关系信息(属于哪个部分),而且几乎没有基于时间的分析(例如,反映某种轨迹的一系列位置读数)。此外,我们实现的一个主要限制是列表中只允许潜在目标,例如双足动物和车辆,因此排除了其他潜在相关行为的对象,例如寻路障碍、机器、电梯和武器。
尽管如此,给 AI 一个对其世界的内部心理意象不仅导致了更有趣和更“真实”的行为,而且还使我们能够克服与行为树相关的主要存储问题之一。
Designer Control
让我们从另一个角度来考虑复杂性,那就是可用性和可指挥性。在这种情况下,我们关注的不是 AI 是否表现得可信,而是 AI 系统的用户——关卡设计师,如何利用系统为玩家打造戏剧性和有趣的游戏体验。
设计方面同样受到复杂性问题的困扰。例如,考虑参数蔓延的问题。有许多不同类型的角色。每个角色都可以执行许多不同的行为。每个行为都受到少量参数的控制。将这些因素结合起来,我们就会看到大量晦涩难懂的浮点数。数以百计的数字中,到底是哪个让某个特定的敌人“感觉不对劲”?确实很难说清楚。
设计师需要告诉 AI 要做什么,但在什么层面上?如果 AI 系统必须由设计师指定一切,那就会太复杂了。然而我们确实需要 AI 能够处理高层次的指导:指示它们整体上表现出好斗或懦弱。同样,在涉及位置控制时,我们希望指示是模糊的:“占据这个大致区域”。
与前面的部分一样,解决所有这些问题的方案都在于一些非常有用的表示。
Character definition
- Model,animation graph
- Behavior parameters
- Static Control
Level-scripting
- Dynamic Control
Static Control
Variety
角色种类
- 精英
- 野猪兽
- 海军陆战队
种类的变种
- 金色精英
- 红色精英
- 侍卫精英
- 飞行精英
所有角色和行为参数都包含在一个 .character 文件中。 该文件提供角色名称,并指定用于身体的几何模型。 当设计师放置一个 AI 时,首先选择要使用的 .character 文件。
粗略计算 Halo 2 ,总共有 64 个变种,每个变种有 80 个行为,每个行为包含 3 个参数来控制。参数总数为 64 * 80 * 3 = 15360。维护如此多的参数,这种情况完全是无法维持的。但如果记住 “设计原则 4:在一个稳定的基础上进行变化” ,我们可以大大减轻设计师的负担。
Parameters
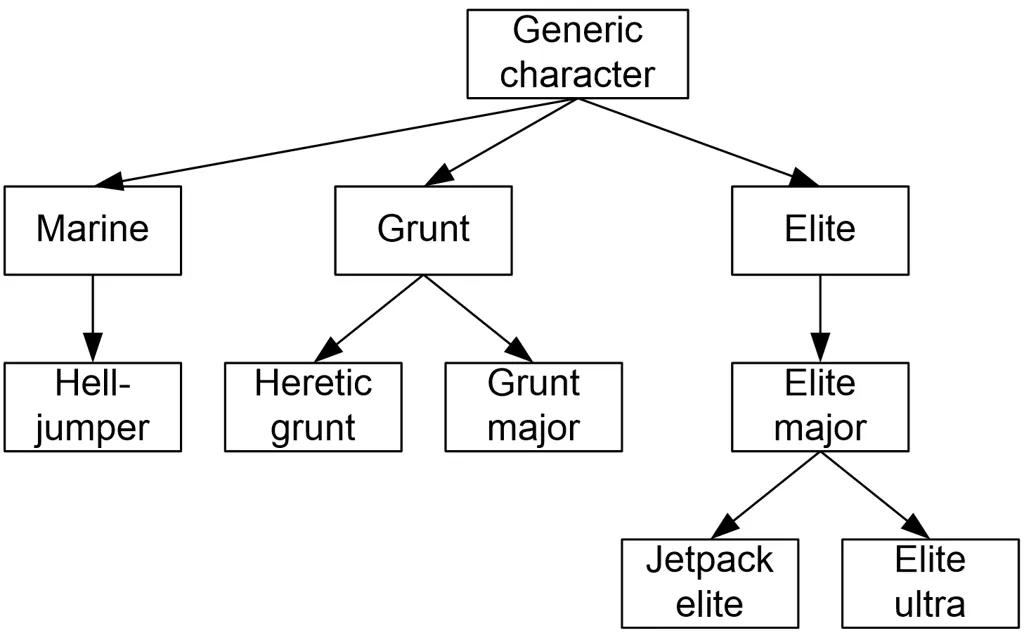
.character 文件不是参数的简单扁平列表。 相反,它是 _参数块(Parameter blocks)- 的列表,每个块以逻辑方式分组以控制行为的某些方面 —— 自我保护块、战斗块、武器设计块等。例如:
- Vitality 类属性
- Perception 类属性
- Search 类属性
- Weapon 类属性
- 等等
但并非所有 character 文件都需要包含所有块。 当 AI 尝试运行特定行为时,如果其 character 文件中缺少相关块,它将改为在引用的父 character 文件中查找。 如果该文件也没有该块,则检查其父文件,依此类推。 这样就形成了一个角色层次结构,其中每个子角色仅定义与其父角色的显著变化。 整个树的根是通用角色,它为所有块定义“合适”的参数值。
Styles
风格(Styles) 代表了我们可以控制 AI 行为树结构的最终、也许是最直接的机制。风格实际上只是一个允许和禁止行为的列表。就像如果一个行为的标签与角色的当前状态不匹配,那么该行为就不能被考虑一样,除非风格明确允许该行为,否则它也不能被考虑。
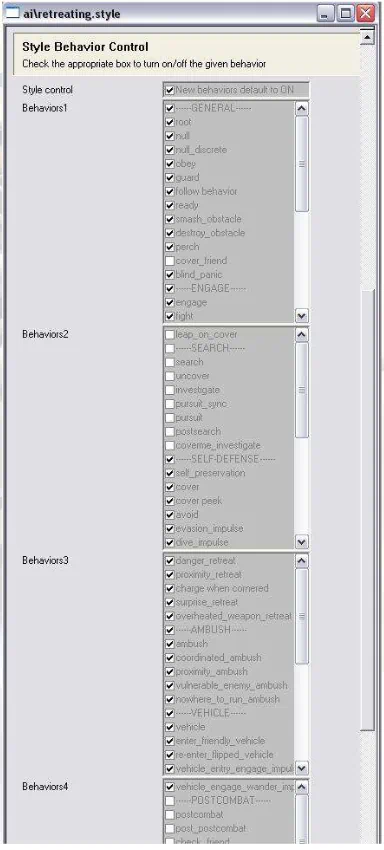
鉴于风格机制的直接性,这是一种非常强大且非常危险的工具。 特别是它可以给 AI 一个实际上不允许运行 任何 行为的风格,或者将 AI 置于极其残废的状态,以至于其行为看上去完全是随机的。 出于这些原因,风格通常不针对每个遭遇战进行编辑的。 相反,设计师有一个小的可用风格库选择使用(库中的每个风格都获得了首席设计师和AI程序员的批准)。 但是除了这一点外,风格还允许一些有趣的变化。防御性风格不允许冲锋或搜索行为。进攻性风格不允许自我保护。非作战风格根本不允许任何战斗行为,而只允许空闲或撤退行为。风格还允许设计师在某些控制行为的参数方面使其倾向于某一方向或另一方向(例如,在胆小的风格中更容易让角色逃跑)。
Dynamic Control (Variation)
Halo 1 使用 遭遇(Encounter) 来实现 AI 在运行时的动态控制。每个”遭遇“包含多个 Actor分组和 可占领区域分组。当一个”遭遇“完成后,将 Actor 和区域 加入另一个”遭遇“。但这个方案面临一个问题:架构上不鼓励将 Actor 从一个”遭遇“移动到另一个”遭遇“。
Halo 2 针对这个问题做了一点改进:
- 小队(Squads):Actor 分组
- 区域(Zones):地区(Area)分组
- 命令(Orders):小队和区域的映射关系。
Orders
“命令”这个术语背后的理念是,它应该体现出类似连长对士兵下命令那样层次的指示。 “我们要占领那座山!” “我们要占领那个碉堡,坚守到援军到来!” …… 这些命令大多属于“去这里做这个” 类型。
去这里:属于 位置指示(Position Direction) 做这个:属于 行为指示(Behavior Direction)
Position Direction: Orders and Firing Positions
在 Halo 1 中4,AI 的位置是通过设计师放置的 射击位置(Firing Positions) 来控制的。射击位置就是 AI 在执行空间行为时可以考虑的离散点。例如,如果一个目标藏在障碍物后面,AI 可以尝试前往一个射击位置,从该位置能直接看到目标当前的假定位置(我们说“假定”,是因为目标可能已经移动)。同理,在执行战斗行为时,也会选择一个适当的射击位置,从而可以向目标射击(再次强调,这个位置必须能直接看到目标,并且与目标的保持适当的距离,距离则由使用的武器类型和其它因素决定)。
当我们开始通过脚本给 AI 在设置一段时间内可用的射击位置集合时,射击位置成为一个极其有用的控制机制。在 Halo 1 中,AI被分组成遭遇,其中包含一组射击位置集合。根据遭遇的状态(他们的盟友是否被杀?他们是否赢了?他们是否输了?这是由设计师创建的映射关系),这个位置集合的不同子集提供给 AI 使用。在 Halo 2 中,基本思想保持不变,尽管表示方式不同。我们不再有一个单一的遭遇结构,而是有了小队,AI 的分组和区域,射击位置的分组。形成两者之间的映射的是一个新结构,称为 命令(Order) 。
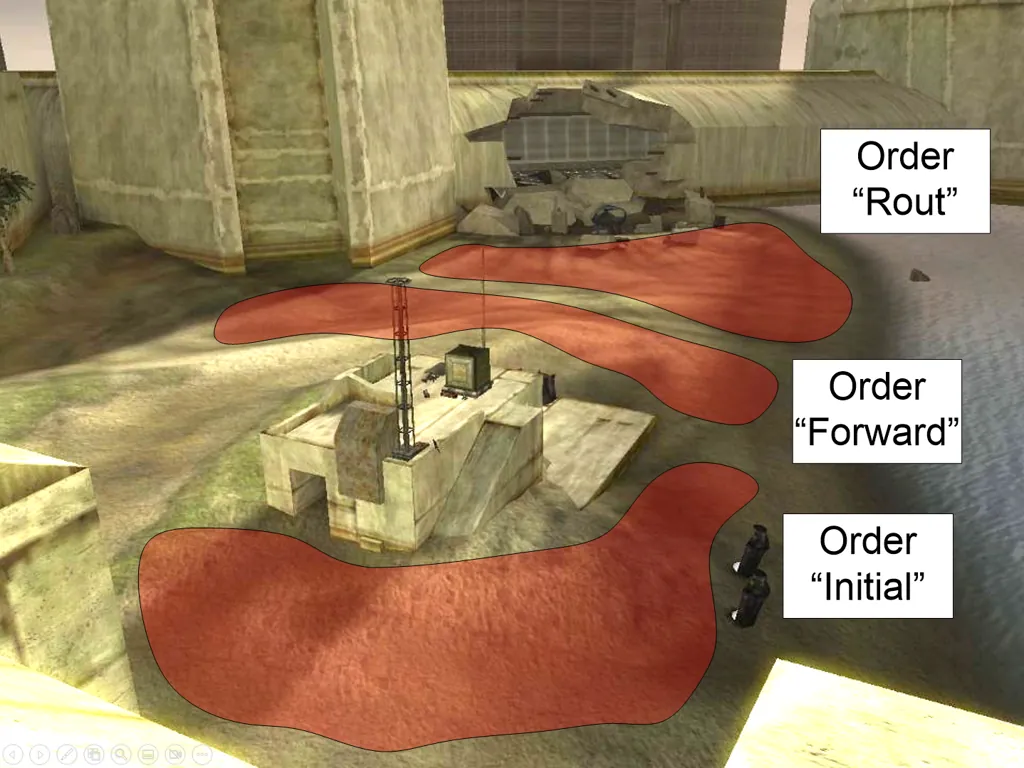
从本质上来说,一个命令只是对一组射击位置的引用。当命令被“分配”给一个小队(Squad)时,由命令引用的射击位置组(Zone)就会对该小队中的AI可用。这是一个简单的机制,稍微复杂一点的是,命令还包含一些基本的脚本功能,允许在命令之间进行自动过渡。设计师可以使用一组可能的触发类型(例如,“是否有x个或更多小队成员被杀?”“小队是否发现了玩家?”)来满足触发条件时,小队将被分配一个与该触发器相关联的新命令。因此设计师可以使用非常简单的高级表示来脚本化战斗的一般流程。
到目前为止,我们描述了命令如何完成指示的第一部分——位置指示(Position Direction) 。
Behavior Direction: Orders and Styles
命令对于第二部分——行为指示(Behavior Direction),也是非常有用的。在 Halo 2 中,设计师可以通过命令包含的专用标记,例如允许或禁止使用载具、潜行攻击以及控制交战规则(自由开火,被动开火等)。
命令还以另一种重要方式影响行为:它们引用了一种风格。
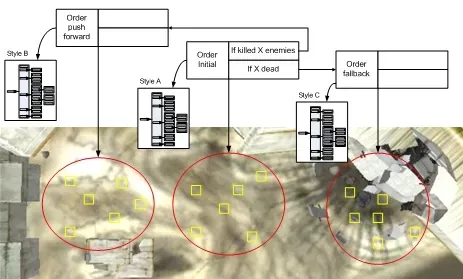 一个小队从名为“initial”的命令开始,根据战斗的进行情况可以转换到“forward”或“fallback”命令。每个命令都引用其各自的射击位置集合和风格,风格可以指示其是否“积极地”,或是“防御性地”,还是“莽撞地”行动。
一个小队从名为“initial”的命令开始,根据战斗的进行情况可以转换到“forward”或“fallback”命令。每个命令都引用其各自的射击位置集合和风格,风格可以指示其是否“积极地”,或是“防御性地”,还是“莽撞地”行动。
命令和风格是我们在游戏中实现遭遇之间变化的主要方式之一。使用这两个工具,设计师能够让相同的 AI 在不同阶段的表现截然不同——理论上符合故事和关卡进展的需求。
Summary
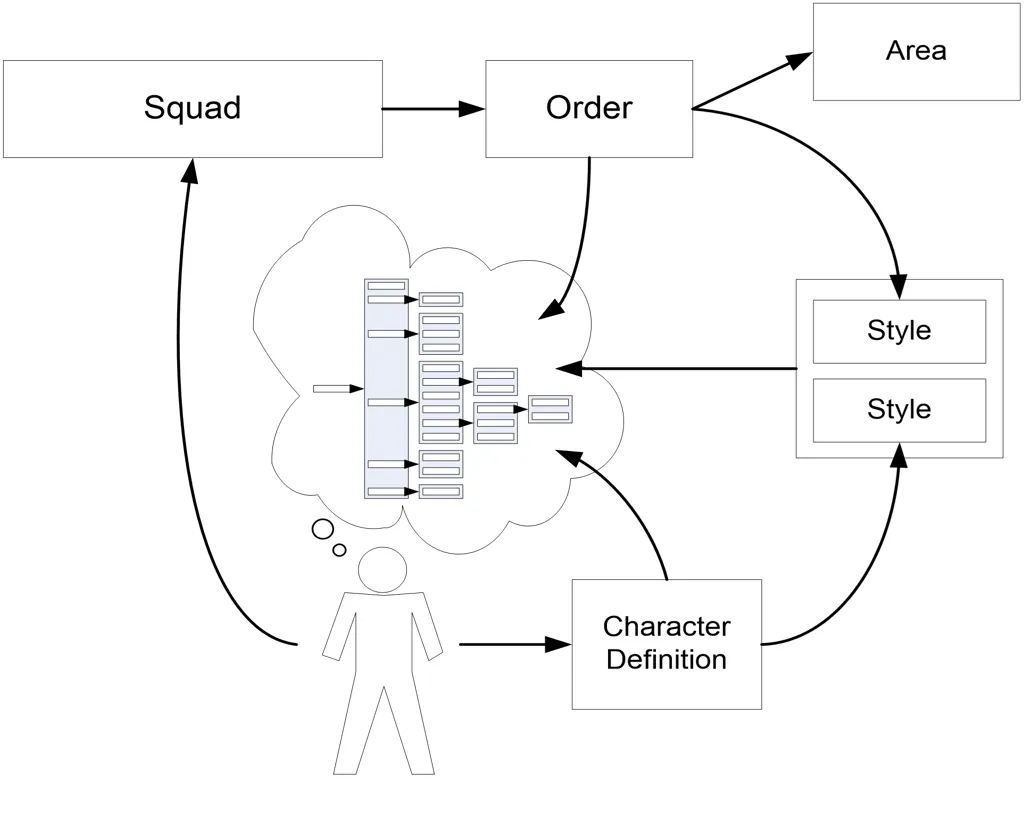
从上述示意图可以看出,设计师可以利用的各种控制结构:
- Actor 大脑中有一棵行为树
- Actor 属于一个小队(Squad)
- 小队被分配一个命令(Order)
- 命令包含一组地区(Zone,一组Area)和一个风格(Style)
- 同时,Actor 也引用一个角色定义文件(.character),它会将行为参数提供给行为树,也提供一个风格。
可以看到图中右侧有两个风格,这就是为什么需要风格可叠加的原因。因为实际开发过程中,我们需要从不同来源组合风格,这两个风格会同时作用在一个角色上,需要可以叠加起来共同影响 AI 的行为。比如,Actor 坐载具内,载具也需要针对载具上的不同座位,使用不同的风格来约束 Actor 的行为。我们不希望 AI 在驾驶坦克和驾驶疣猪号侦察车时表现出完全相同的行为。
以上就是设计师控制相关的论述,我们了解了不同控制结构的协同工作,以及风格的可叠加性在其中发挥的作用。由此引入第五条设计原则:
设计原则 5:与你的表示形式协同工作。
在设计和实现AI系统时应该与所使用的表示形式密切合作。通过深入了解并充分利用系统的表示形式,可以更好地理解系统的结构和行为,并更有效地管理和处理系统的复杂性。
结论
- All systems need to “play ball” with the core decision mechanism
所有系统都需要与核心决策机制"合作":以“行为树DAG”为核心决策机制,设计简便易用的子系统与之相辅相成,协调运转。
- Not looking for “smart” architecture, looking for expressive architecture
不要追求“更智能”的架构,而要更具表达能力的架构:设计的系统架构能够有效地表达其功能和特性,而不是单纯追求智能。
本文中列出的“设计原则”是对一些想法进行结构化的尝试,尽管这些有趣的想法看起来像个杂乱无章的大杂烩。总的来说,我们希望强调两个主要观点:首先,我们会以多种方式为系统的复杂性付出代价,包括运行时、实现、用户体验和可用性。其次,解决复杂性问题的关键始终是表示问题。这里描述的所有技巧都涉及到如何使用便捷易用的表示结构,无论是行为DAG、命令、风格还是角色层次结构。这是一篇符合 AI 论文的“觉悟”,因为这不过是对学术 AI 长期以来所知道的一个观点的重新阐释:通过明智地使用正确的表示形式,可以将困难的问题变得微不足道。
-
这正是 Utility AI 的一个不足之处,诸多条件即使用了归一化的量化手段,也很难产生合理的行为。 ↩︎
-
G. Alt, “The Suffering: A Game AI Case Study”, in the proceedings of the Challenges in Game AI Workshop, Nineteenth National Conference on Artificial Intelligence (AAAI), 2004 ↩︎
-
R. Burke, D. Isla, M. Downie, Y. Ivanov, and B. Blumberg, “CreatureSmarts: The Art and Architecture of a Virtual Brain,” in the proceedings of the Game Developers Conference, San Jose, CA, 2001. ↩︎
-
J. Greisemer, C. Butcher, “The Integration of AI and Level Design in Halo”, in the proceedings of the Game Developers Conference, San Jose, CA, 2002 ↩︎ ↩︎