面向数据的行为树(4):面向数据的行为树概述
这篇文章是 Bjoern Knafla 撰写的系列文章《面向数据的行为树(Data-oriented Behavior Tree Series)》 第4篇。文章原载于AltDevBlogADay,AltDevBlogADay 是一个技术文集,主要由游戏业界老兵们于2011-2014年撰写。原站已经关闭,即使时隔多年,很多文章仍值得一看。
系列文章目录
《面向数据的行为树》系列文章介绍了作者在面向数据的行为树设计过程中的思考和探索,以下是系列文章的目录:
- 面向数据的行为树(1):行为树入门
- 面向数据的行为树(2):震惊!面向对象行为树并不面向数据
- 面向数据的行为树(3):数据导向流催生的行为树
- 面向数据的行为树(4):面向数据的行为树概述
- 面向数据的行为树(5):行为树结构剖析
前言
上一篇关于面向数据行为树的文章对许多人来说太长,很难找到足够的时间完整阅读。我自己也会有困难抽出足够时间和精力完全消化它。因此,剥离面向数据设计的诸多实践内容后,这篇文章就是上篇文章的高层次概述。
动机
目前和未来硬件中,相比计算机在寄存器中的数据计算,内存访问和数据移动具有更高的成本(能量和时钟周期)。到主内存的内存带宽是有限的。测量以处理器周期为单位,内存访问速度和计算性能之间的差距是一个令人恐惧的鸿沟(夸张的说法)。缓存未命中和/或从主内存而不是 CPU 缓存获取数据的必要性是计算的瓶颈,并且可能窃取运行在其他核心上的计算任务的内存带宽。
依赖于节点指向其他节点的传统层次结构的行为树(BT)实现,在遍历树时很容易导致许多随机内存访问。每次随机内存访问都是一个潜在的缓存未命中(Cache Miss),这意味着等待数据并浪费时钟周期。
另外,如果叶节点调用的动作处理大量的数据,那么会发生更多的缓存未命中——请求的数据到达 CPU 时可能会逐出行为树数据,一旦树遍历继续,则需要从主内存中恢复。
虽然许多行为树的使用在性能分析器中不会看到其遍历的影响,但我们想了解并学习如何构建更高效的硬件和更面向数据的行为树,从而使许多实体(Entity)运行大量的行为树,甚至在 PS3 的 SPU 上。
在开发过程中,快速迭代和支持游戏 AI 的监控和调试是提高游戏性(玩家体验)的一个重要因素。我希望游戏运行时的行为树支持实时调整,而不是因为行为树变化,需要重新编译,重新启动游戏。
要点概括
为了满足在游戏中快速遍历行为树,以及快速修改和开发期间观察游戏的需求,我们使用两种不同的行为树表示形式,分别用于运行时和开发时。
运行时
使用3类动作:
- 即时动作 :在遍历行为树实例时立即调用,但只对 Actor 的隔离和私有数据起作用。 Actor 的知识聚合在黑板中,这是一个合理和自包含的数据块。 隔离的数据支持并发处理多个 Actor ,如果数据易于移动且小得足以适合本地存储,则不会过分破坏缓存。
- 延迟动作 : 处理挖掘大量数据的动作,或者适合批量处理数据的动作,这些动作不应该立即调用,而是先收集运行请求,再延迟处理。缓存未命中在行为树遍历期间应该最小化,非统一内存地址空间(如 SPU 的本地内存或图形设备内存)应该与延迟动作一起工作。
- 持续动作 :因为推迟执行造成了动作的延迟,要在下次行为遍历后才能收到和响应状态的更新,因此引入持续动作。 它会在没有显式调用的情况下通过行为树遍历持续运行,并且始终可以立即访问其最后的行为结果状态。
限制即时动作仅访问 Actor 的黑板,延迟动作执行,并引入持续动作。基于节点和指针的行为树实现也可以使用这些设计。
为了摆脱节点在树结构上下追逐指针的随机内存访问,可以通过预先遍历将图形展平为节点数组—— 流。
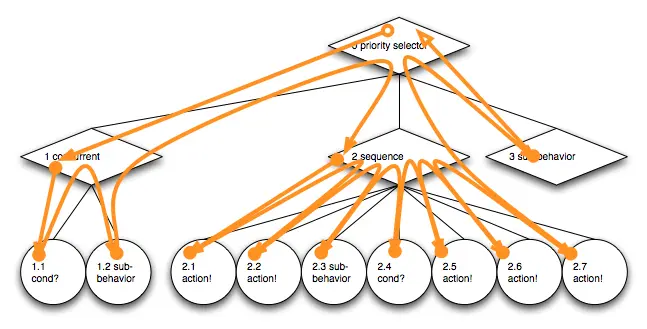
这个流描述了行为树的静态 形状(shape) 。
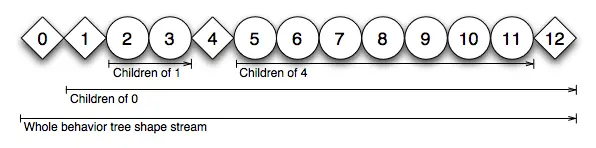
形状流的遍历主要是向前遍历的(如果父节点中止时子节点(即子行为)被放弃,则会向后跳转,停止正在运行的动作),子行为流可能会跳过。因此,数据的流式传输甚至预取是一种选择。 由于行为树的分支性质,前向跳过可能会减少数组存储方法的性能收益。
每个行为树实例,也称为Actor,都有自己的遍历状态(例如,上次遍历期间哪个序列的子节点正在运行,以便在下一次决策更新期间再次访问)和 动作状态(准备运行(ready),运行中(running),成功完成(success),没有副作用的失败(fail),有副作用的错误(error)),这些都是基于静态形状流。只有内部节点(非动作节点)有一个遍历状态。 由于所有内部节点决定如何遍历 Actor 的行为树,因此决定运行哪些动作,所以我将它们的状态称为 决策器状态(decider state) 而不是 遍历状态(traversal state) 。
状态(用于动作和决策节点)包含与其对应的形状项索引,并根据索引以递增顺序排序。 为了更新 Actor 的决策过程,解释器(一种虚拟机(VM)或处理内核)从 Actor 的行为形状流的开头开始遍历。 如果当前访问的节点没有找到状态,则使用其默认状态。 这种方式可以存储较少的状态数据。相比始终为每个形状节点存储状态,这个方案降低了状态数据移动的带宽需求。
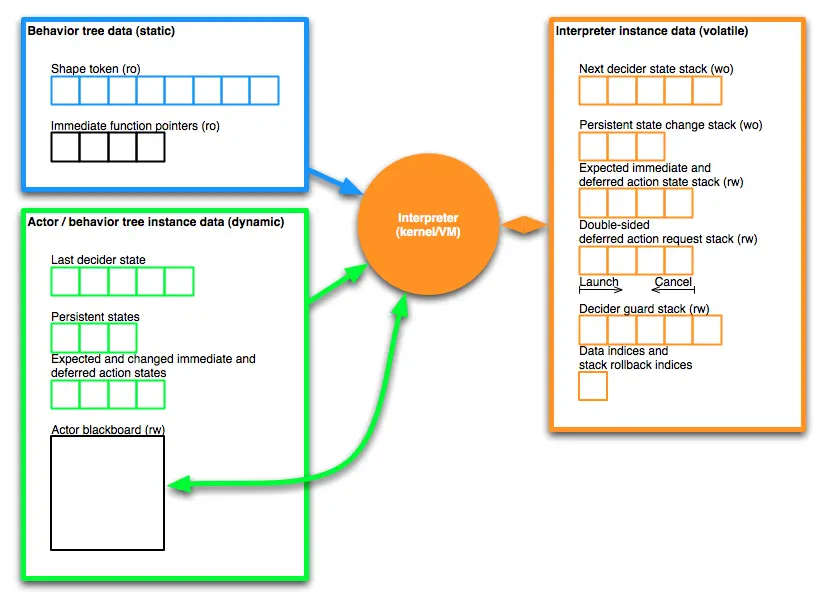
通过分析行为树的静态形状,能够确定动作和决策器状态的数量。 因此可以进行必要的内存预分配。
编辑时
我们将在后续文章继续研究编辑时。 主要考虑的内容有:
- 使用易于创建和修改的行为树表示。 在编辑器中,不需要由 Actor 每帧多次遍历。
- 在编辑时行为树表示与运行时流之间建立连接,从而启用运行时的监控和收集统计信息。
- 在连接后,收集编辑端的更改,将其存储在增量更改命令队列,并发送到运行时以实时应用修改。
- 增量更改命令能够针对数据适时调整,比如存储在动作和决策状态中的形状项索引范围,以及行为树运行时与执行延迟和持续动作的系统之间的映射。
执行
行为树系统在每个更新期间按四个阶段运行:
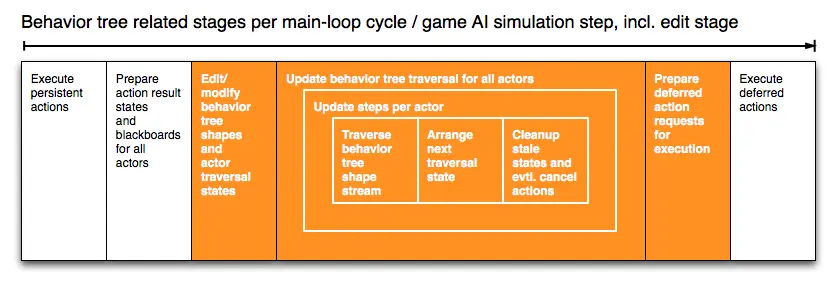
- 收集延迟和持续动作触发的动作状态变更。 将 Actor 黑板更新。
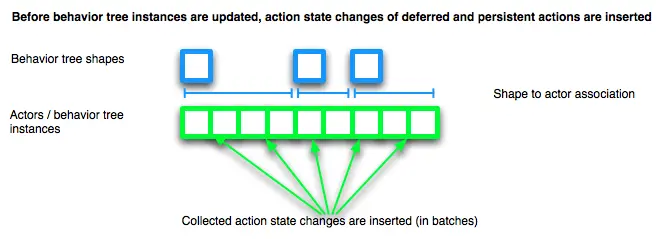
- 将编辑更改应用于受影响的行为形状流,及其 Actor 动作和遍历状态。
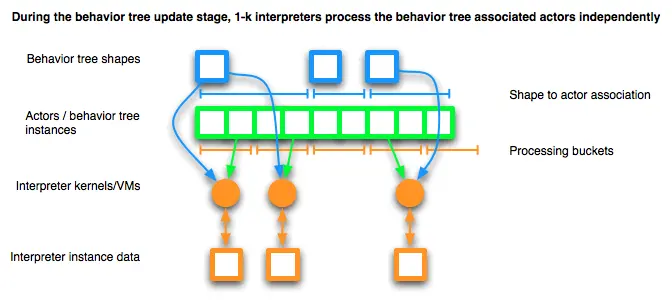
- 遍历与不同行为树相关联的 Actor ,尽可能并发执行。
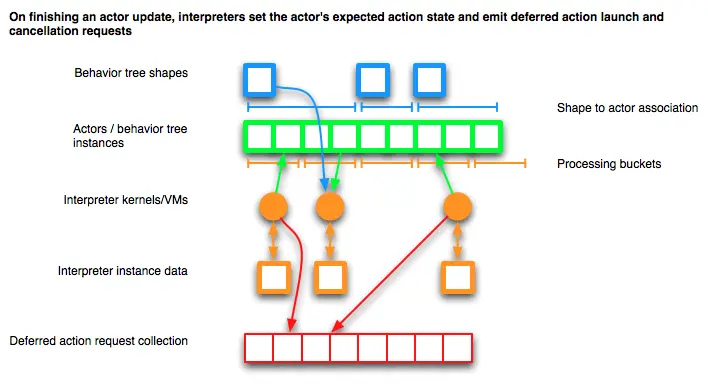
- 将收集的动作执行和取消请求分发到各自的系统。
决策更新由解释器执行,也可以称之为内核,或工作在行为树形状、决策,以及动作状态流上的虚拟机(VM)。
每个解释器都有一组专用的工作数据来:
- 收集当前处理的 Actor 的动作请求。
- 存储正在运行的即时和延迟动作的动作状态。
- 将内部行为树决策器压入和弹出到决策器守卫堆栈上,以跟踪遍历节点的父节点链 (范围),并根据父节点类型和决策器状态(例如,上一个遍历的子节点)处理行为结果状态。
- 在离开内部节点并因此弹出决策器守卫堆栈时,存储更新的决策器状态。
在完成 Actor 更新时,一个解释器:
- 用新生成的状态替换存储在 Actor 的上一次动作和决策器状态。
- 向行为树系统的共享动作请求队列发出动作请求(以启用对所有 Actor 的动作排序和批处理)。
- 为每个请求的动作添加运行状态,以跟踪 Actor 希望接收动作状态更改的运行延迟动作。
- 清理易失性辅助缓冲区和堆栈以准备处理下一个要更新的 Actor 。
尾声
正如巴黎射击游戏研讨会1上了解到的那样,面向数据的行为树已经在整个行业中被广泛使用。但是目前尚未听说过一个允许实时编辑的行为树设计,这似乎是我们应该实现的主要目标。
另外作者已经有一个设想:通过事件而不是为每个更新遍历它们来驱动行为树,然而也并不确信增加的复杂性会带来性能收益。由于篇幅所限,这个主题留待以后的更专业的文章。
感谢 2011年巴黎游戏 AI 会议上告诉我文章太长,以至于无暇阅读的所有人,你们完全正确,我会试着写更短但希望仍然有用的文章。
特别感谢 AngryAnt2 与我就 Behave3 及我自己的方法进行的精彩讨论。他还激励我画更多图表!
参考资料
-
巴黎射击游戏研讨会(Paris Shooter Symposium)是一个由 Game/AI Conference 组织的研讨会,专门致力于第一人称和第三人称射击游戏以及战斗游戏。 ↩︎