面向数据的行为树(3):数据导向流催生的行为树
这篇文章是 Bjoern Knafla 撰写的系列文章《面向数据的行为树(Data-oriented Behavior Tree Series)》 第3篇。文章原载于AltDevBlogADay,AltDevBlogADay 是一个技术文集,主要由游戏业界老兵们于2011-2014年撰写。原站已经关闭,即使时隔多年,很多文章仍值得一看。
系列文章目录
《面向数据的行为树》系列文章介绍了作者在面向数据的行为树设计过程中的思考和探索,以下是系列文章的目录:
- 面向数据的行为树(1):行为树入门
- 面向数据的行为树(2):震惊!面向对象行为树并不面向数据
- 面向数据的行为树(3):数据导向流催生的行为树
- 面向数据的行为树(4):面向数据的行为树概述
- 面向数据的行为树(5):行为树结构剖析
前言
如何使行为树及其分支、情境依赖性遍历以及它们的非规则数据访问模式与游戏平台的内存层次结构协调?如何将数据导向设计付诸实践?在运行时进行快速迭代和行为调整又该如何实现?
这些问题激发了作者对面向数据的行为树的探索。在第一篇文章中,我们了解了行为树的概念,在第二篇文章中,我们理解了平台的内存系统对发挥性能的关键作用,面向数据思想,以及如何适应这一编程思想,现在是时候将这些知识付诸实践了。
目标和需求
功能需求
行为树是一种工具,也是一种模型。它可以描述 Actor 的行为,并将整个决策过程分解为多个行为的组合。行为节点也具有明确的语义,它可以影响行为树的遍历方式,从而影响 Actor 的决策过程和执行结果。它的功能应该具备:
- 易于创建、理解 Actor 的决策过程;
- 简化行为的重用,具备重用的行为库;
- 能够实现游戏内 AI 行为的快速迭代、调试、优化;
- 提供直观的调试信息,最终实现AI内部运作信息的可视化。
性能需求
一款游戏可能只有几个,或者有数百到数千个,由行为树控制的实体(也称为 Actor)。在这两种情况下,游戏人工智能(AI)通常每帧只有很少的时间预算,行为树不应该夺走”导航“和”视线感知“所需的计算时间。宝贵的计算周期也不应该浪费在等待数据进入 CPU 核心寄存器上。对于我们这个实验,在运行时实现高效的决策制定和角色控制,以下因素至关重要:
- 最小化缓存碎片,减少随机内存访问,警惕内存访问延迟1;
- 可以将 Actor 的行为树数据作为一个整体或逐块地移动到计算核心的本地内存中2;
- 节约内存带宽,保持较低的内存需求,利用内存分层结构内的数据共享;
- 了解最坏情况下的内存使用情况,预先分配内存并简化在游戏主机上的运行;
- 不要失去对调用堆栈深度的控制;
- 利用并发的优势。
总结起来就是,在游戏建模或开发阶段要求灵活性和快速迭代,而游戏运行阶段则要求执行效率和高性能。这些需求在很大程度上是相互对立的,因此此次尝试的前提条件是:对行为树的开发时和运行时表示使用单独的表示,然后再将二者巧妙地连接起来,两全其美,代价就是更大的代码量和复杂性。
运行时的行为树
在使用行为树决策时,Actor 会检查其自身和世界的状态,来做出判断。可能我们无法绕开条件判断和分支,但可以尽量减少它们的影响,最大程度地避免非预期数据引起的缓存抖动。
那么如何使用面向数据的思想来设计行为树,就需要了解需要什么样的输入数据和输出数据,以及如何组织数据来完成输入到输出的转换。
- 输出:行为,即 Actor 可以执行的具体动作(Action),如 行走至某个位置,进攻某个目标等等,同时这些行为也会影响游戏的各种状态。
- 输入:世界状态和 Actor 行为树的状态。
- 转换:更新 Actor 的行为树。就是说通过更新行为树就可以将 Actor 所感知的世界状态 以及它的行为树状态作为输入,转化为 Actor 的行动,即输出,这就是决策的过程。
输出
简单的行为树在遍历到叶节点的时候,可能会执行诸如寻路,环境感知,动画生成等数据密集型的行为,这些与行为特定的数据会破坏行为树执行时的缓存。同时这些动作也会对游戏状态产生影响,行为树作为通用的建模工具,无法明确用户会定义什么行为,会访问什么数据。
延迟动作和动作请求流
因此,动作不应该在访问叶节点时就被调用,而是相关的系统里延迟调用。这样我们可以集中这些数据进行批量处理(batching)之类的优化(并行)处理。
延迟处理也有不足之处:动作的选择和执行在运行时刻和代码逻辑上都是分开的,不仅增加了调试复杂度,还带来了延迟。当遍历到执行动作的节点时,动作节点的返回状态不会立刻返回 “成功”/“失败”这样的最终结果,而是返回 “运行中(Running)”的状态。行为树在此次遍历的最终状态也会是 “运行中”状态,而正在执行的动作也许在下次遍历或者更晚的时刻完成执行。当它完成执行返回最终的结果时,树的遍历就会继续执行下去。
持续动作
通过遍历记录和动作的调用统计,可以确定一部分几乎每次都会执行,比如感知相关的动作:寻找视野内的敌人,侦听周围的枪声等等,我们称之为持续动作。通过将这些持续动作分离出来,并始终在树遍历之前执行,我们可以摆脱延迟,虽然其中的一些结果可能在这次遍历时不会被用到。当遍历到这类节点时,可以直接返回其先前执行结果对应的状态(一般为“成功”状态)。在遍历期间,代表持续动作的节点通常会返回成功状态——它们已经完成了工作,遍历可以继续进行。但是,也可能存在其他返回状态,例如反映某个动作需要多个更新周期才能完成,或者表示特殊感知动作“失败”,因为它无法检测到附近的实体。
即时动作
也有一些动作不会作为行为树的节点,但作为其他系统的组件时刻在运行。它们为 Actor 收集世界知识,因为行为树依靠准确的世界知识来做出更好的决策。条件节点会检查 Actor 的黑板(Blackboard)来获取特定信息,如评估过的感知数据(例如,视野内的敌人数量,目标是否装备RPG),最终会影响树的遍历。如果 Actor 的相关数据适合 CPU 缓存,那么延迟这些动作就没有意义。因此这些只访问 Actor 私有数据的动作,我们称之为即时动作,在树的遍历期间可以立即执行而无需延迟。
遍历状态
每个 Actor 的行为树在遍历时会产生相应的内部状态,这些状态影响下次的遍历结果。例如,Sequence 节点会因为上次的“运行中”状态,在这次遍历时会继续执行下个子节点。因此,树的遍历状态是一种输出数据,它可以作为输入反馈来影响下一次遍历。
输入
我们已经了解到,行为树更新所需的输入有以下几种:
- 持续动作和延迟动作的结果状态;
- 即时动作和条件节点所使用的 Actor 私有数据,即黑板;
- 上一次行为树遍历后的内部状态;
- 行为树结构或形状本身(称之为 Shape)。
动作结果状态数组
存储动作结果状态可以这么处理:为每个 Actor 定义一个数组,用来保存其延迟动作和即时动作的执行结果。行为树的形状决定了动作到状态索引的精确映射(见下文)。每个动作请求结果都是特定于角色的,由于每个动作的执行结果分别在数组的各自位置上,可以并发执行这些动作而不必担心竞争条件。
为每个可能的动作结果状态固定一个槽位还可以用于检测哪些动作在上次更新期间未被重新访问。一个动作可能已经返回了运行状态,但是另一个执行它的请求尚未发出。通过将返回状态数组与动作请求缓冲区进行比较,我们可以发出 取消请求 ——如果需要的话。如果对应的动作在更新期间未发出,那么所有结果状态都需要被重置为 ready 状态,以确保它们不会持续返回先前的成功状态。例如,之前几个模拟步骤中处于成功状态的某个动作始终返回成功,通过重置其状态为 ready,可以保证其在每次更新时都会被重新触发。
动作结果状态队列
动态大小的动作结果状态也可以存储在队列中。根据其关联动作节点的遍历顺序对状态进行排序,我们可以加快对它们的访问速度。由于不是每次更新都会请求所有动作,因此此方法需要更少的内存来存储结果状态。
如果行为树系统无法找出哪些先前请求的动作未再次请求,例如因为遍历跳过了发出它们的节点,则动作处理组件需要自行检测此类缺失的重新激活的和取消的节点,或者只执行请求的动作,而不而不存储更新步骤之间任何持续动作的请求。
私有黑板
如果只针对优化了低延迟和条件计算的 CPU,如大多数的 x86 兼容处理器。我们可以使用 void 无类型指针或 any 类型表示 Actor 私有数据,然后在访问之前再显式转换其类型。若行为树的遍历更新是在 Cell 处理器的 SPU 上,或者通过 OpenCL 或者 CUDA 在 GPU 上,我们就需要更多黑板数据类型的信息,以便将其从 主内存( main memory) 移动到 本地存储(local storage),或者从 主机内存(host memory) 移动到 设备内存(device memory) 。它可以是特定大小的数据缓冲区,或者是简单的字典类型描述,就像 Niklas Frykholm3 在他的 AltDevBlogADay 文章 《Managing Decoupling Part 3 – C++ Duck Typing》4 中提出的那样。
虽然行为树结构和 Actor 遍历状态是每次更新的输入数据,但它们的表示受到遍历过程的影响。
数据处理
扁平化处理
让我们再次看一下这个系列第一篇文章中的示例行为树:
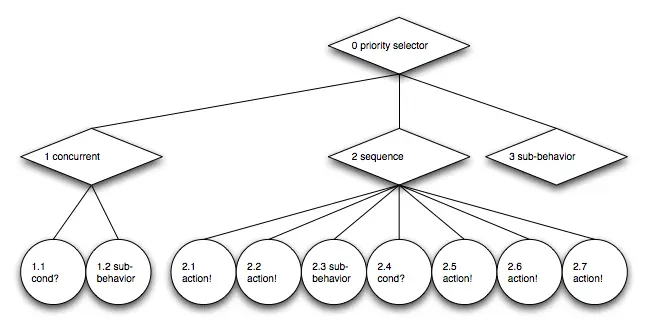
根节点是一个优先选择器,它会重新运行返回 running 状态的子节点,而不是每次从第一个子节点重新运行。节点 3 是一个子树的占位符。
让我们跟踪第一次遍历的路径:
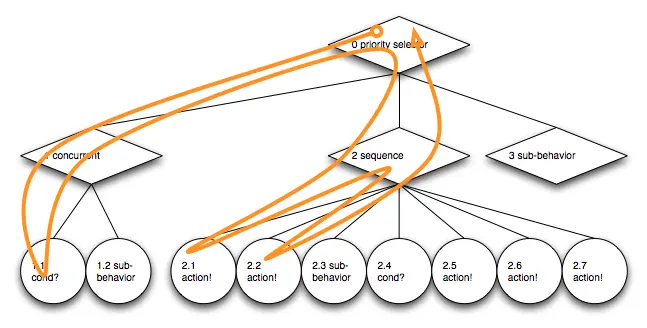
在更新过程中,优先节点 0 首先尝试执行其第一个子节点:并行节点 1。然而它的第一个子节点 1.1,一个检查 Actor 黑板数据某个条件的 即时动作,失败了。遍历返回到根优先节点,然后尝试下一个子树:序列节点 2,访问其第一个子节点 2.1。这个 即时动作 返回 success,因此序列接着运行子节点 2.2,它发出一个延迟动作请求并返回 running 状态。序列节点同样以 running 状态退出,优先节点也是如此。第一次遍历完成。图中橙色线条表示遍历路径。
通过行为树的遍历留下的路径作为它的踪迹。行为树更新从其根部开始,这是一个深度优先的遍历,然后由内部节点的遍历语义控制。在进入时访问每个内部节点。基于内部节点的更新语义,可能会访问其中一个子节点。从子树返回时,再次访问内部节点以对返回的子节点结果状态做出反应,决定是进入另一个子节点,还是离开内部节点?在节点 2 和它的子节点之间的之字形线条明确展示了这个内部节点到子节点再返回的遍历过程。
如果按照深度优先的方式遍历整个树,即访问每个节点而不考虑内部节点的遍历语义:
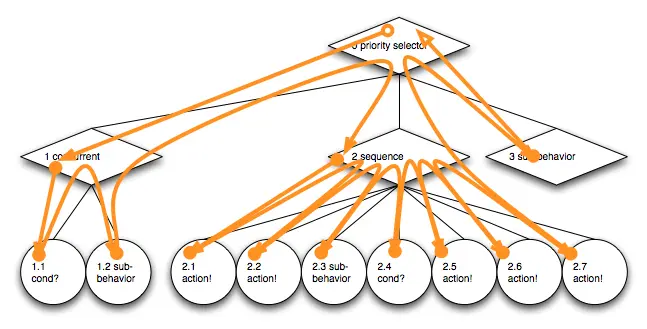
在每次访问节点时,我们为其分配一个编号。分配的值从一个节点到另一个节点递增。从编号为0的根节点开始,我们对所有节点进行编号:
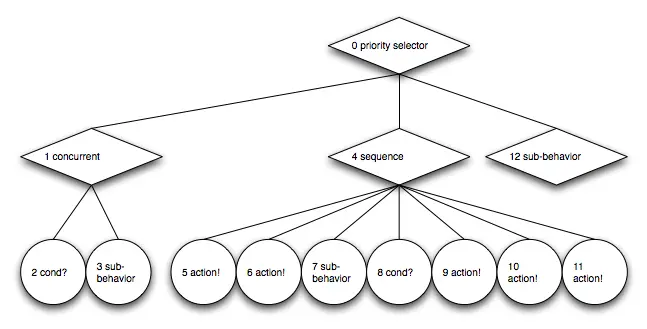
为了简化后续的遍历图,删除了节点类型名称,并缩小了节点符号:
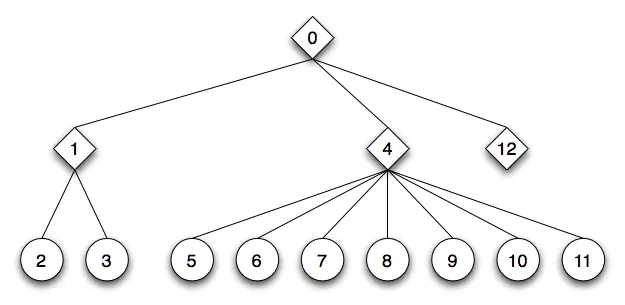
现在,将每个节点的编号解释为数组或流中的索引。整个行为树被扁平化为一系列连续的标记,代表节点的普通数据结构(POD)。内部父节点标记始终位于其子节点的扁平化子树之前。这个 行为流(behavior stream) 描述了行为树的结构,虽然它是扁平化的,它的形状也称为 行为树形状标记流(behavior tree shape token stream) :
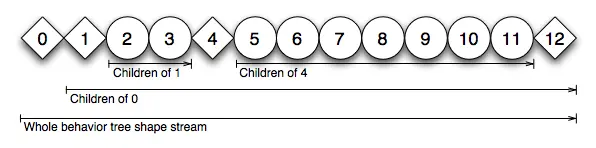
由相同行为树控制的所有 Actor 共享其 形状(Shape)。但 Actor 的遍历状态是基于其自己的世界知识,所以它是不共享的。
典型的树遍历通过从索引为 0 的根标记开始迭代流。代表内部节点的标记影响迭代,例如通过跳过扁平化子树所占用的索引范围,来直接跳转到最后要运行的子节点。跳转到子节点意味着迭代到子树的根节点标记的索引。
当一个子树返回时,其父节点需要对结果状态做出反应,以决定是继续下一个子树(之字形)还是离开并将遍历决策权交给更高级别的父节点。如何跟踪父节点及其遍历语义,从而对返回的状态做出反应?一种解决方案是 纯流 或 形状流 的方法,另一种方法涉及到遍历栈。这两种方法都允许从形状标记到形状标记的迭代,并保持函数调用栈平坦。处理标记时会调用一个基于标记类型的相关函数。在离开函数后,轮到流中的下一个标记。简单地遍历行为树会调用每个节点的更新函数 update() ,该函数本身调用子节点的更新函数,后果是:无法控制函数的调用栈深度。
纯流遍历
最直接的之字形处理方式不仅在行为流中存储一个单一的节点标记,而且在内部节点的每个扁平化子树后面存储一个额外的标记。这些特殊的 守卫 标记存储了如何对子树的结果状态做出何种反应信息,它们“守卫”着这些子树。一个序列守卫标记会在 fail 的返回状态下跳转到最后一个子守卫标记后面的那个标记,这个标记表示序列子树及其所有直接和间接子节点的标记范围的结束。跳转将会落在序列的父节点的守卫标记上。我们称这个处理内部节点的语义和范围的方法为 “纯流遍历法” 。
下面是包括守卫标记的扁平化示例(在其相关节点的编号后面标有“g”),橙色线条表示遍历方向和遍历轨迹:

回到上面的示例,这次我们用字符 A 到 K 标注遍历 0 的每个节点访问:
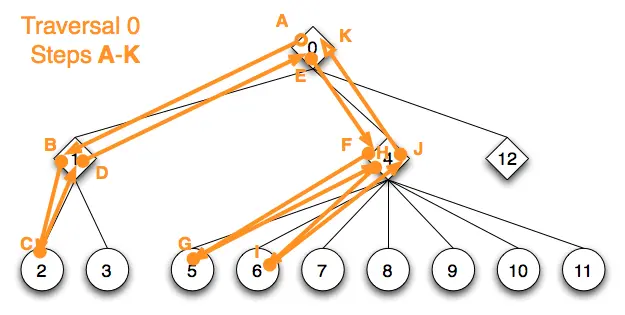
这是对应的纯流遍历:

我们没有明确标记出守卫标记,只显示其内部节点的符号和编号。纯行为形状标记流是单向迭代的,沿着相同的迭代方向,未访问的节点标记会被跳过。
下一次行为树更新从根节点上次 running状态的子节点开始遍历。该子节点,即序列节点 4,遍历状态指示遍历到它的最后 running 的子节点,即节点 6,其发出的动作已经以 success 状态完成,并为 Actor 设置了该状态。因此,遍历继续到节点 7 的形状标记,该标记发出一个延迟的动作请求,并立即以 running 状态返回。行为标记节点 4 和 0 也以 running 状态相继退出。
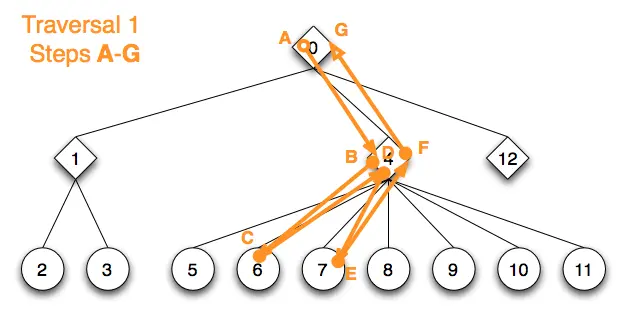
使用纯流表示法,本次遍历如下所示:

节点 1 及其子节点和子守卫标记的整个结构被跳过。序列节点标记 4 直接跳到它上次 running 状态的子节点,即节点 6 的标记,以继续更新遍历。它返回了 success 状态,节点 4 的守卫标记决定在序列中继续前进,到达标记 7。标记 7 请求了其相应的延迟动作之后,其后面的守卫标记会以 running 状态离开序列,并跳到下一个节点 0 的序列守卫标记。这个守卫标记也以 running 状态退出了 。遍历 1 完成。
使用遍历栈进行遍历
处理这种之字形跳跃的另一种方式是使用形状标记的行为流,行为流中每个节点仅包含一个标记。在更新过程中使用 遍历栈(traversal stack) 将当前表示内部节点范围的形状标记压入/弹出。我们可以分析行为树,以确定所需的最大遍历深度,从而确定所需的栈大小。
在遍历形状标记流时,每当遇到/进入内部节点标记时,就会将一个栈标记推送到遍历栈上。在处理完形状标记后,会检查顶部遍历栈标记。它定义了上一个处理的形状标记所属的父节点,并决定如何处理上一个处理的形状标记返回的状态。它还包含有关其内部节点直接和间接子节点的索引范围信息。因此,它可以确定最后处理的标记索引是否仍属于内部节点索引范围。
为了退出内部节点,将弹出遍历栈,增加流迭代索引以离开内部节点及其子节点的索引范围,并且(如果存在的话)新的栈顶的标记处理退出的结果状态。它可能选择进入其下一个子节点的首个形状标记进行遍历,或者像上面描述的那样退出,依此类推。
让我们再次看看以下深度优先展平的行为树示例:
优先节点 0 的遍历栈标记知道它的子树跨越从0(栈标记本身的内部节点)到12的标记索引范围。内部节点1的遍历堆栈标记跨越从1到3的索引范围,而序列节点4的栈标记的索引范围从索引4到索引11。例如,如果节点5返回success的结果状态,那么其直接父节点4的栈标记会看到它仍在其范围内,并且流迭代应该继续到标记6。但如果节点11的标记返回success,则栈节点标记会检测到它是序列节点4的最后一个返回的子节点,因此将退出序列,并且序列的父节点的栈标记应决定遍历如何继续。
将一个栈标记视作一个守卫,可为内部节点的所有子节点重复使用。
这就是 遍历栈方法 。下面结合遍历状态处理,展示了一个示例行为树遍历。
纯流遍历 VS 遍历栈遍历
由于除了根节点之外的每个节点都是一个子节点,并且每个子节点标记都有一个守卫标记,因此对于纯流方法,存储的形状标记数量增加了一倍。虽然在执行 Actor 遍历时不需要栈,但是在纯流方法中需要的内存较少。由于栈只需要保存与行为树深度相同数量的标记,因此遍历栈所需的内存量比纯流方法少。
对于具有大量内存带宽但每个核心的本地缓存较小的平台,第一种方法更合适,而对于每个核心具有更大的本地缓存以及内存带宽可能更少的平台,遍历栈思想更为合适,因为它们可以将遍历栈保存在核心高速缓存中,并且由于行为流形状所需内存较少,可能会被多个运行核心的工作线程共享,这些核心共享缓存。
遍历的状态
Actor 的遍历状态需要被保留,以便下次遍历可以从上次 running 状态的行为处继续运行,而且还要记下装饰节点的计数/计时信息。
没有并行节点的行为树同时最多只有一个running的动作。在纯流表示法中,我们只需要存储一个节点标记索引,表示从哪里重新开始遍历。上次running标记后面的守卫标记引导遍历向其后的行为树结构执行。在遍历栈方法中,遍历范围,即行为树中的遍历位置,被编码在遍历栈中。保留此堆栈以进行下次遍历,并从遍历堆栈顶部的标记的上一个running的子节点重新开始。
并行节点语义使状态存储复杂化
当并行节点语义进入画面时,Actor 的行为树更新之后,多个运行中的行为可能会共存,需要在开始下一个更新遍历时考虑它们。一个单一的形状标记索引不再足够开始下一个遍历了。由于在执行时并行节点会更新所有子节点,因此需要知道最高的并行节点(?)以从它开始下一个遍历。并且为了遍历到正确的节点,例如在序列中上次运行的子节点,需要访问并收集该子节点的状态。状态收集和处理与遍历堆栈方法类似,下面会作更详细的解释。
每个节点一个状态槽
具有多个活动子节点的并行节点将遍历堆栈转换为一个状态堆栈树,以反映其所有running状态的动作节点的遍历状态。动态存储状态树似乎不太友好,因为我们已经将行为树形状扁平化为数据流,我们也可以将状态树扁平化成 状态流 ,其中每个条目与一个形状流标记相关联。
仅在必要时对上次访问的节点缓存其状态
基于堆栈的遍历始终从行为树根开始,并使用状态流将遍历导向上次更新步骤期间处于running状态的行为。在最简单的情况下,每个需要记住其状态的节点可以在状态流中拥有自己的数据槽。一个更复杂、占用内存更少的解决方案是:只在节点标记的状态与对应节点的默认初始状态不同时,才存储其状态。例如,只在序列开始遍历时存储序列的下一个子节点。这还意味着我们只会为上次遍历时访问过的节点存储状态,而不是为每个节点提供状态槽。
在离开内部节点时收集状态
上述两种情况都使用了缓存来存储上一次行为树遍历的状态。对于大多数内部节点,我们只需要在离开节点时获取其遍历状态,即在最后一个成功运行或返回 running 的子节点之后。然而在离开内部节点时,它的许多直接和间接子节点可能已经被遍历过,其中许多已经保存了自己的状态。因此它们的父节点的遍历状态会排在所有子节点状态之后。如果给每个形状标记分配一个固定状态槽,这个方案可以跳回到形状标记,但会导致遍历期间出现大量的随机内存访问,这不是我们想要的结果。
从形状标记状态槽中收集状态
为了保持对形状流和遍历状态数组的前进,只需在所有直接和间接子节点的状态槽之后添加内部节点的状态槽。在 Actor 更新后的清理阶段,我们可以把状态移动到其节点状态范围的开头。
从动态状态缓冲区中收集状态
如果没有使用每个节点一个状态槽的做法,而是使用一个状态收集缓冲区,收集并保存所有形状流中的标记索引和遍历状态。在行为树更新遍历后,将缓冲区重新排序,无论是根据其中存储的形状标记索引进行排序,还是通过后向迭代,使用特殊的遍历堆栈以反转遍历状态的顺序。我们将在后续文章中见到这种方法更详细的描述。这种重新排序产生了一个可以完全向前遍历的遍历状态流。
在下一次遍历期间,形状流和遍历状态流一起迭代。在当前遍历的形状标记索引与当前状态标记中存储的形状索引相对应的时候,它会被读取,并且两个流的标记索引同时递增。如果当前状态标记中存储的形状标记索引大于当前遍历的形状流索引,那么我们会进入之前不活跃的子行为,因此没有对应的状态可用,只能使用形状的默认初始状态。一旦当前遍历跳过了具有状态流条目的行为树的某些部分,我们就会检测到当前形状索引大于当前状态流标记的情况。然后只需沿着状态流运行,直到遇到对应的形状索引等于或大于状态索引。
装饰节点的遍历状态
不要忘记,如果装饰节点的设置与其默认值不同的话,我们始终需要保存它们的状态,比如计时器或计数器。这些状态可以折叠到主状态流中,也可以有自己的缓冲区。作者更喜欢后者,假设这类节点的数量很少,而且可以轻松适应 L2 Cache 或 SPU 的本地存储,那么在这个特殊的状态缓冲区里前进和后退应该不成问题。即使装饰节点不是一直更新的,其计时器始终需要进行维护,所以我们将这些遍历状态称为 持久 状态。
行为流遍历示例
使用遍历堆栈和缓冲区收集节点遍历状态
现在抛开抽象描述,让我们把所有的内容都放到一起。利用已经介绍过的行为树遍历示例,我们来研究遍历堆栈和遍历状态如何引导对行为树形状标记流的迭代。快速回顾一下遍历步骤 0 是什么样子的:
Traversal 0 Step Start:以下是所有由同一行为树控制的所有 Actor 共享的形状流,以及遍历堆栈,上次遍历状态流和下次遍历状态缓冲区:
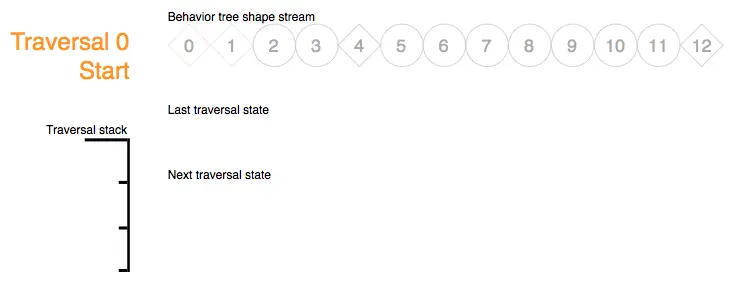
上次遍历状态流为空,所有节点都处于默认初始遍历状态下。例如,序列节点将从第一个子节点开始遍历。
形状标记的符号是暗淡的,这是由于它们在遍历步骤 0 期间尚未被遍历到:

Traversal 0 Step A: 第一次迭代步骤进入优先节点根节点 0 的标记。没有关联的遍历状态,它访问了第一个子节点 1。优先节点是一个内部节点,因此将一个优先节点的遍历栈标记压入到遍历堆栈上:

Traversal 0 Step B:步骤 B 处理了节点 1 的形状标记。并行节点需要对其子节点的行为结果状态做出反应。为此,它将自己的遍历栈标记压入堆栈:
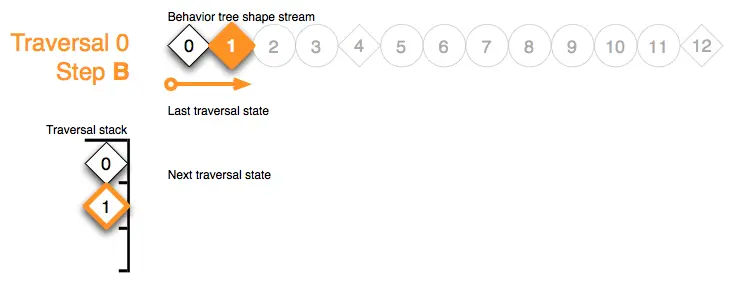
Traversal 0 Step C:并行节点从左到右运行其子节点,并且只在子节点返回 fail 或 error 状态时提前退出。子节点 2 的即时动作形状标记更新并返回 fail :
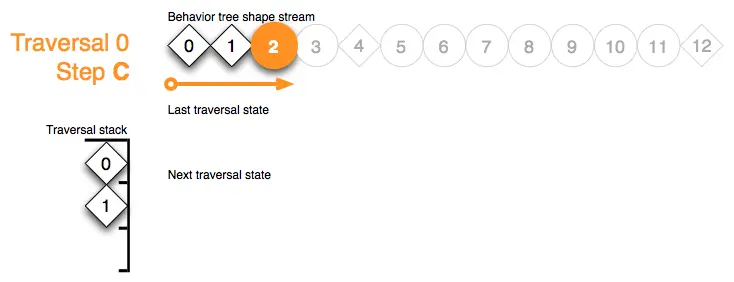
Traversal 0 Step D:在步骤 D 中,并行节点 1 通过其遍历栈上的标记,对子节点的 fail 结果作出反应。它决定也使用 fail 状态放弃。这意味着遍历堆栈被弹出(请参见步骤 E 中的效果),形状流迭代器向前推进,离开并行子树的索引范围。由于并行节点始终会尝试重新运行所有子节点,因此不需要存储遍历状态:
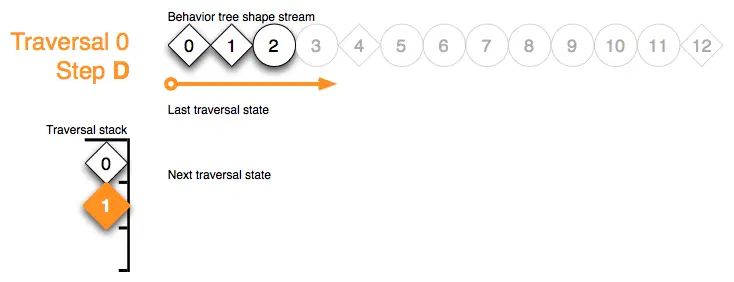
Traversal 0 Step E:在弹出遍历堆栈后,我们立即检查(重新)出现的堆栈顶部的标记,执行其对应节点的遍历语义,上一个子节点的行为返回状态是什么,流迭代器是否到达堆栈顶部标记对应的流范围的末尾?在目前情况下,遍历仍在节点 0 的索引范围内,并且已推进到第二个子树的起始标记 4。由于第一个子节点失败,优先节点尝试运行这个子节点:
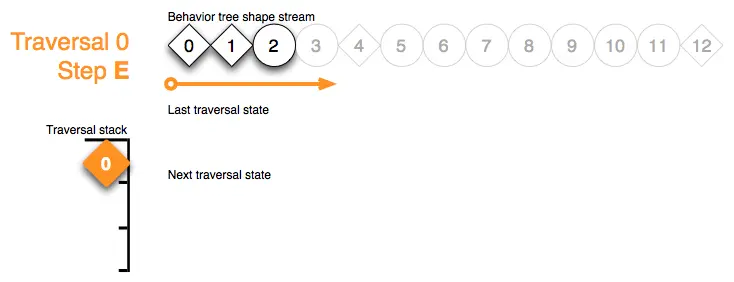
Traversal 0 Step F:处理序列节点 4 的标记,将它的堆栈标记压入遍历栈,并将流迭代器推进到它的第一个子节点 5:
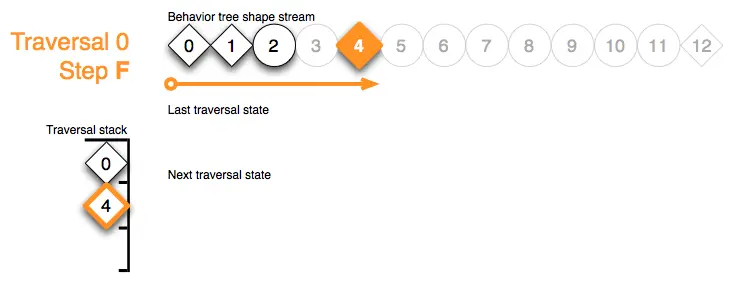
Traversal 0 Step G:在步骤 G 中,处理即时动作标记 5 成功,并将形状流迭代器推进到节点 4 的下一个子节点:
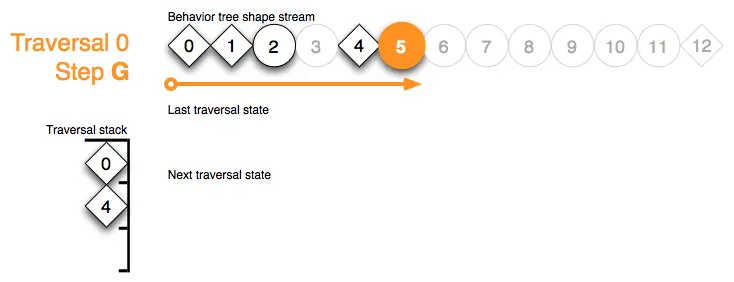
Traversal 0 Step H:一如既往地,在处理形状标记后,顶部遍历栈标记被解释,要对上一个返回的行为状态做出反应。对于序列标记4来说,它可以安全地遍历到下一个子节点6:
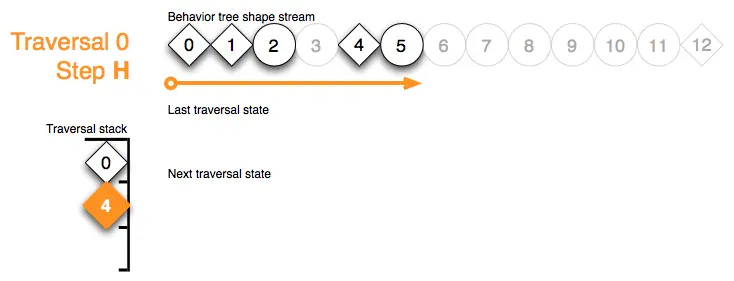
Traversal 0 Step I:节点 6 的形状标记在步骤 I 中发出了延迟动作请求,并返回结果状态 running:
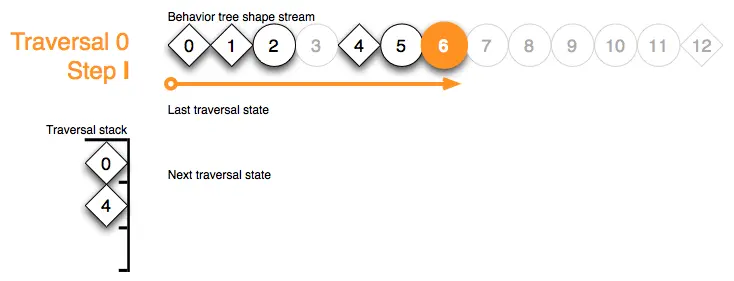
Traversal 0 Step J:步骤J包括处理序列节点4的顶部堆栈标记。由于子节点返回 running 时,序列会退出,它会将形状流迭代器推进到节点 4 的子节点(和它们的子节点)范围的末尾。为了下次更新作准备,序列的遍历状态,即上次正在运行的子节点,被添加到下次遍历状态缓冲区中。退出序列时也会弹出其遍历栈标记:
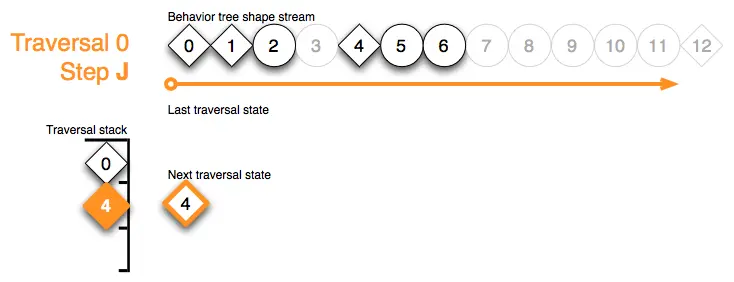
Traversal 0 Step K:弹出遍历堆栈后,处理新的顶部遍历标记,发现优先节点0的堆栈标记,它最后尝试的子节点返回 running 状态,因此它也以 running 状态退出。为此,它首先将其上次正在运行的子节点记录在下次遍历状态缓冲区中,然后弹出遍堆栈,并将形状流迭代器推进到其范围的末尾:
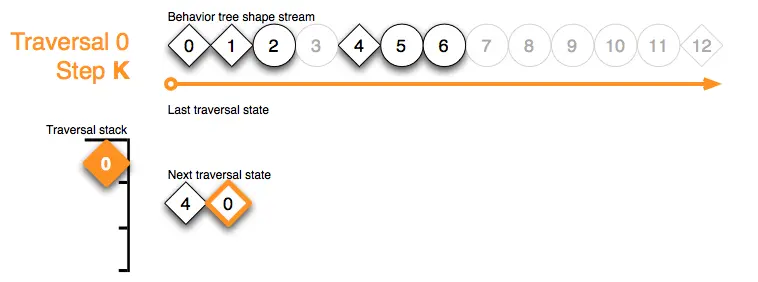
Traversal 0 Step End:在步骤K中,形状流的末尾已经到达。更新遍历0结束:
In step K the end of the shape stream has been reached – update traversal 0 ends:

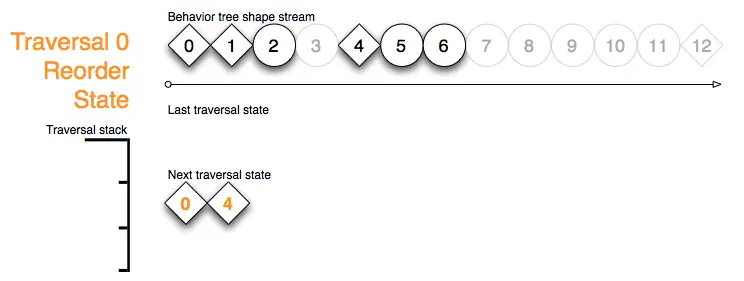
为下一次更新做准备,下次遍历状态缓冲区被重新排序:
下一轮,以下是下一个更新,遍历1的路径:
Traversal 1 Step Start:在开始更新遍历1之前,重新排序的下次遍历状态被复制为上次遍历状态流,并清除下次遍历状态缓冲区:
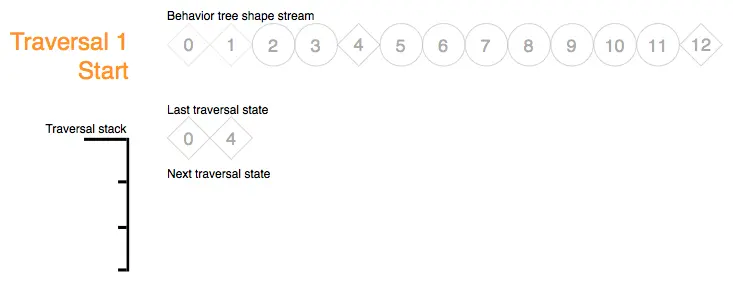
Traversal 1 Step A:遍历1的步骤A处理形状标记0,它在 上次遍历状态流 上检测到上次遍历状态。节点的遍历堆栈标记被压入到遍历堆栈上,形状流迭代器被推进到上次running的子节点4,并增加 上次遍历状态流 的迭代器:

Traversal 1 Step B:在步骤B中,形状标记4发现了它的上次遍历状态,增加上次遍历状态流迭代器,将形状流迭代器跳到它上次running 的子节点6,并压入一个遍历堆栈标记到遍历堆栈上:
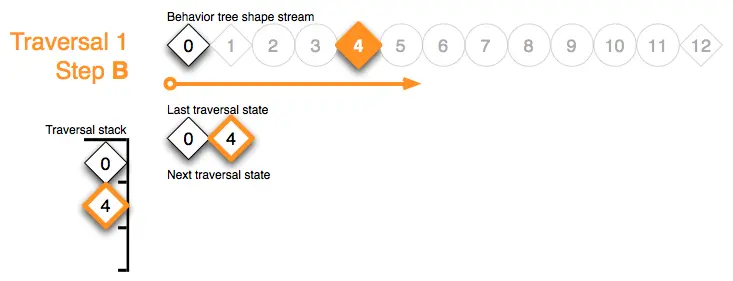
Traversal 1 Step C:自上次行为树更新以来,通过形状标记6请求的动作已经执行并成功:
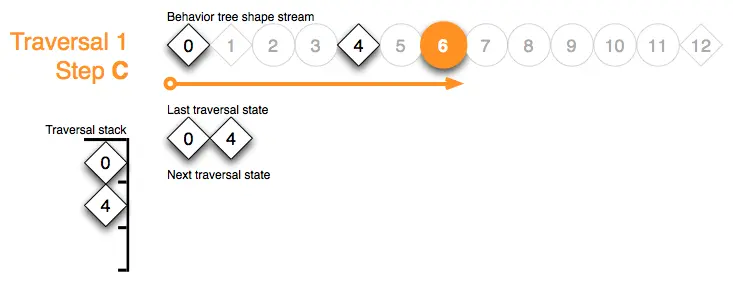
Traversal 1 Step D:序列节点4的堆栈标记允许其前进到子节点7:
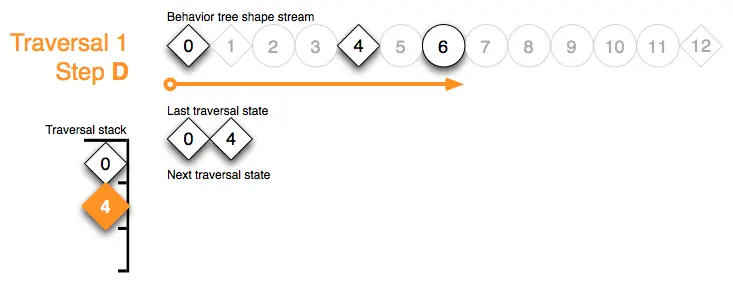
Traversal 1 Step E:形状标记7为 Actor 请求了一个延迟动作,并返回一个 running 的行为状态:
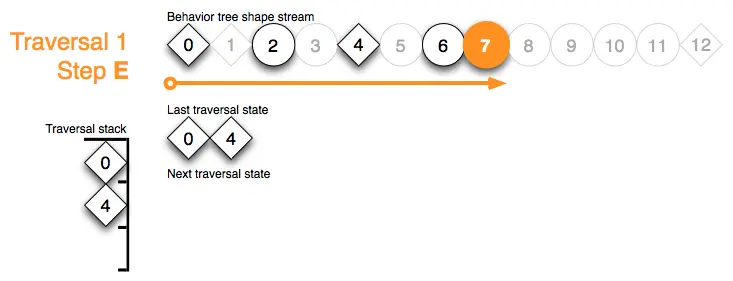
Traversal 1 Step F:处理完每个形状标记后都会检查顶部遍历堆栈标记。堆栈标记决定退出其序列形状流的索引范围,将序列4的遍历状态添加到下次遍历状态缓冲区中,并返回running状态。弹出遍历堆栈(请参阅步骤G的效果):
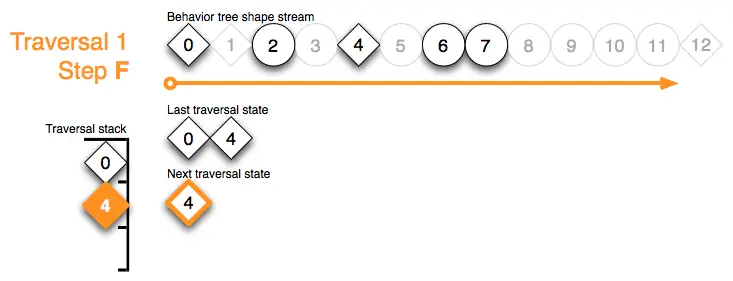
Traversal 1 Step G:一如既往:弹出遍历堆栈后会检查新的顶部堆栈标记。优先节点0发现它的子节点以 running 状态退出了。因此,它的工作也完成了——在下次遍历状态缓冲区保存下一次遍历要从哪个子节点开始,将形状流推进到它范围的末尾,并弹出遍历堆栈:
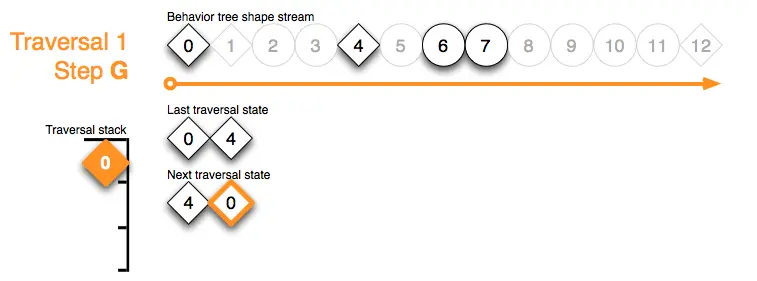
Traversal 1 Step End:遍历1结束,已经到达形状流的末尾,并且遍历堆栈为空:
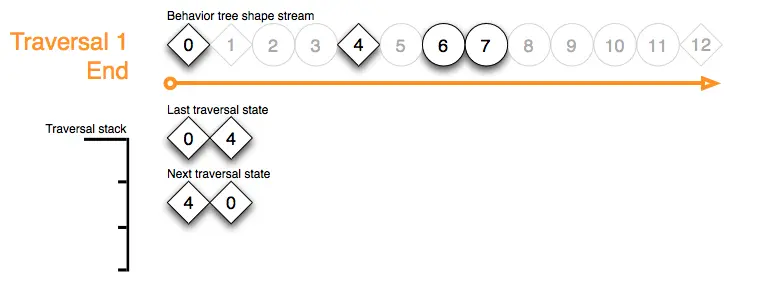
我们将下次遍历缓冲区重新排序,然后结束遍历示例:
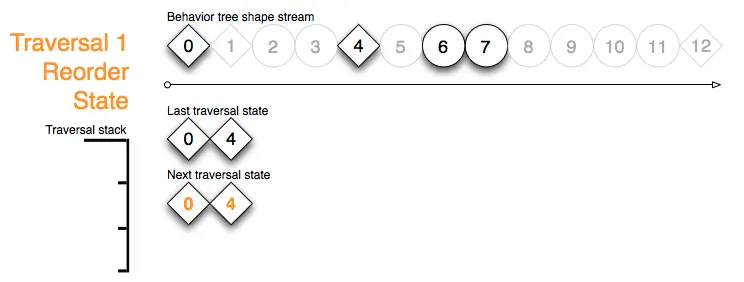
请记住,行为树形状流中的节点标记、遍历堆栈和状态缓冲区都是不同的数据类型。而且遍历状态标识了序列或选择节点要运行的下一个子节点,或者包含了装饰节点的计数器或计时器,而节点返回的行为结果状态指定了相关行为是 成功(success) 、 正在运行(running) 、 失败(fail) 还是发生了 错误(error) 。
行为流处理
这真是一个相当漫长的过程。让我们总结一下我们得到的东西:
- 行为树的结构,也就是 形状(Shape) ,由 形状标记(shape token) 构成的行为流表示,这种基于形状标记的表示法对使用同一行为树的所有 Actor 都是共享的。
- 每个行为树包含一组每次更新要运行的持续动作。
- 为每个 Actor 保存的一组持续和延迟动作的结果状态。
- 在遍历 Actor 的行为树之后,生成了一个由游戏的其他系统或组件运行的动作请求集合。每个请求包含足够的信息来识别 Actor ,并在动作完成时写回对应的结果状态。
- 上次 Actor 更新遍历状态存储在状态流中。可以用第二个状态缓冲区来保存装饰节点的长期状态。
- 一个私有黑板包含了 Actor 特定的聚合世界知识。黑板条目可能由持续动作产生。这些条目由即时动作读取,也可能写入。
排序流形状标记、状态缓冲区、以及状态流,从而实现简单的单向流迭代。每次遍历都会生成一个新的遍历状态流和延迟动作请求缓冲区。简而言之:行为树、 Actor 的遍历状态、动作请求完全用数据表示,并且数据存储在数组中。不需要指针,只需要索引来遍历行为流。Actor 的行为树遍历将这些数据转换并生成下一次遍历数据。这有点像一个虚拟机(VM)在指令和数据流之间处理,或者像数据流通过计算内核。
对所有 Actor 的行为树进行更新,可以分为多个阶段,如下图所示:
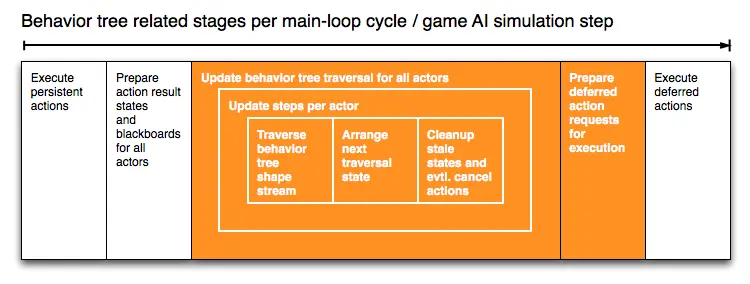
橙色阶段由行为树组件/系统直接控制,而白色块表示与行为树交互的阶段,但它们受其他组件/系统控制。
在每个游戏 AI 模拟步骤中:
- 执行所有 Actor 特定的持续动作。
- 返回并设置相关 Actor 的持续和延迟动作结果状态( 成功(
success) 、正在运行(running) 、 失败(fail) 等)。为了简化条件的实现,只有 Actor 的即时动作可以访问其黑板,因此更新角色世界知识黑板。5 - 然后运行所有 Actor 的决策过程——遍历它们的行为树。
- 每个 Actor 遍历其行为形状标记流、上次遍历状态流,并生成延迟动作请求和下次遍历状态。
- 接下来,对下次遍历状态集合进行排序,以便在下一次更新时成为上次遍历状态流。
- 每个 Actor 的清理阶段可能会检测以前运行的动作是否需要取消,是否需要将未更新的状态重置以便稍后遍历,以及激活但未访问的装饰节点的定时器也会被更新。
- 然后合并所有 Actor 的所有动作请求,并准备将它们送至特定组件。
- 在游戏 AI 模拟步骤结束时,组件以数据优化的方式执行它们收到的动作请求。
行为树的形状在遍历过程中不会被修改,每个 Actor 都在其上次和下次遍历状态,以及动作请求缓冲区中独立工作。因此,为了利用平台的本地存储或只读形状流的共享缓存,共享行为树形状的 Actor 应该一起进行批量处理。每个 Actor 可以独立于其他 Actor 进行处理。通过将 Actor 处理视为一个任务,这些更新任务可以并行运行。我们只需要同步来合并所有角色的动作请求,这样我们就可以对其关联组件或系统的请求进行排序、分块和批处理。
动作请求的结果状态针对不同的 Actor 或每个 Actor 的不同结果状态插槽,可以顺序或并行写入而无需保护措施。
最后但同样重要的是——为了确保重点清楚,必须要再次重复一下—— 形状和状态标记都是普通的数据结构(PODs)。类型 id 指示如何处理它们,每个类型如何影响遍历。标记流只是一个数组,可以轻松地移动、分块、批处理或流入 SPU 的本地存储甚至 OpenCL 或 CUDA 设备内存。尽管仍然需要根据类型 id 进行分支来调用正确的函数来处理每个标记,但是没有虚函数表,数据可以紧密地打包在内存中,而无需进一步的指针间接引用和多态引起的的随机内存访问。既然节点类型的数量是已知且有限的,就没有必要为了继承的灵活性而付出代价。
内部节点的形状标记只访问 Actor 的行为树数据。持续和延迟动作在其与行为树无关的内部组件中运行。即时动作只对 Actor 的世界知识黑板进行操作。因此,这应该指导动作的实现,使数据使用清晰,并最小化更新 Actor 时因不可预见和不可控的数据访问而导致缓存失效的可能性。
流设计看起来可以消除许多随机内存访问。即使有跳过未遍历子树流范围的向前操作,它也可能允许预取。然而,只有可测试的实现才能显示它是否优于更简单的方法。平台的 CPU 架构越”精简“,例如缺少乱序执行指令或分支预测,预期的性能提升就会越明显。
编辑时的行为树
行为树——决策制定的模型——在开发或编辑时精心制作。能够查看行为树以理解角色的行为,与创造行为树同等重要。行为流概念为游戏运行时提供了高效而直接的行为树遍历。类似如何创建它,如何向节点添加和删除子树,如何在代码中编辑,如何通过脚本桥接或GUI(图形用户界面)编辑它的问题,直到现在都被我们忽略了。但这些都是重要的问题,游戏 AI 是一门需要大量试错的手艺和艺术。
调整行为和快速的迭代周期对于构建玩家的游戏体验至关重要,它可以让游戏开发者立即在游戏中看到变化的效果。能够监控 AI 控制角色的决策过程,这极大地帮助了解它的推理逻辑及其可能的缺陷。如果在开发阶段没有很好的控制和跟踪能力,即使运行时的速度很快也没有太大意义。
编辑只是创建了行为树的结构——一个运行时流的蓝图或方案——而被它控制的 Actor 只在调试或行为监控时才进入画面。如果行为树方案的更改立即由运行时行为流以及受影响的 Actor 在运行中的遍历和动作结果状态进行调整,那也非常好。
输出
我们在开发时需要行为树提供什么?
在编辑时,它应该生成运行时行为流和有关 Actor 遍历状态和动作请求缓冲区的最小尺寸的信息。
为了适应游戏内流和 Actor 遍历与标记状态对行为方案变化的适应,需要一种变更或增量命令流。为运行时的行为形状和 Actor 遍历状态维护不同的增量命令队列也许是明智的。
一种输出是行为树方案的可视化。在模型-视图-控制器(MVC) GUI 架构中,所有模型更改都需要传递给控制器及其连接的视图。应该可以将方案视图连接到运行中的角色,并可视化其行为,以及其行为树的遍历。在某种意义上来说,发送给模型观察者的消息是(不同的)增量命令,因此我们也许可以使用相同的机制来收集运行时和 GUI 的更改命令。可视化主要关注父节点与其子节点之间的层次关系,而不太关注树遍历导向的流组织。
另一个所需的输出是序列化格式,将行为树保存到文件或数据库。或许内存流化的运行时行为流可能是一个很好的存储格式,特别是它也很容易从游戏本身加载。
输入
存储行为树涉及要写入的数据,这也是要读取回来的数据。我们可以从行为运行时流创建行为树方案。
在编辑时,从 GUI 或通过脚本绑定接收修改命令。节点被创建,添加到父节点,从父节点移除,并最终被销毁。GUI 中的鼠标点击可能会请求有关节点的更多信息,例如名称或文本描述。
为了能够在编辑时创建持续、延迟和即时的动作,我们需要知道所有可以调用的动作,可以通过从游戏中查询可用的动作列表,也可以通过游戏的配置文件。
在游戏中监视 Actor 时,可能会收到它们请求的动作、当前遍历状态,甚至最终遍历路径的信息。
数据处理
必须承认,到目前为止,我们几乎把所有的时间都放在了行为树运行时流上,只有几次短暂的思考投入到了编辑时方案中。本节大部分是一些零星的想法,以及需要考虑的要点的集合,而不是连贯的分析。
在行为树的开发过程中,一切都围绕着行为层次结构的创建和编辑展开:根据给定的参数,创建和销毁不同类型的节点,例如请求延迟动作,并将这些节点插入到父节点或从父节点删除。这些操作可以在 C/C++ 代码内部完成,可以通过脚本调用,还可以通过 GUI 启动。节点之间的关系是核心数据,除了开发人员在头脑中创建新行为树或试图理解给定的行为树方案以外,不会发生任何遍历。
运行时需要从方案中获取的信息有:
- 行为流的大小。
- 每个流标记的配置。
- 每个 Actor 在一次更新中需要的动作请求缓冲区大小。
- Actor 更新所需的遍历栈大小。
- 所涉及的持续动作有哪些——每个 Actor 预期会收到多少个预更新结果状态。
- 预更新最多会收到多少个延迟动作结果状态。
- 需要多少持久性遍历状态存储槽位,例如装饰节点的计时器。
使用行为流作为文件或序列化格式,我们可以通过遍历形状流中的所有标记(不跳过任何标记)并使用守卫标记或遍历栈来重新创建行为层次结构,从而生成一个方案。通过反向的深度优先遍历方案层次结构可以存储一个方案。
行为树方案的更改应反映在流和连接的游戏运行时的Actor状态中。编辑时组件需要了解建立的上一个行为流配置——方案的最后一个运行时化快照——并根据该快照收集增量或更改命令,以修改形状流,每个Actor的持久性和延迟动作结果状态缓冲区,持久性和最后遍历状态,并且还需要更新受影响的每个Actor更新的遍历栈大小。在将这些命令队列提交给运行时之前,它们会按照应用顺序进行排序:
对于行为树方案的变更,它应反映到流和游戏运行时的 Actor 状态中。编辑时组件需要知道最后建立的行为流配置(方案的最后一个运行时快照),并基于此收集增量命令或变更命令,以修改形态流,每个 Actor 的持续动作和延迟动作结果状态缓冲区,持续和上次遍历状态,并需要更新受影响的每个 Actor 更新的遍历栈大小。在将这些命令队列提交到运行时之前,要根据应用顺序对它们进行排序:
- 对每个行为流、Actor 以及更新任务使用的缓冲区和流大小进行调整。如果变更命令流可能增大,导致修改空间大于最终容量,则设置更大的修改缓冲区。
- 移除每个 Actor 的形状标记及其关联的状态槽。
- 在变更后将索引更改为新的范围。
- 将标记移动到流和缓冲区中的新位置。
- 添加新的形状标记,甚至要添加新的状态以在调试时控制运行时行为树遍历。
分析增量命令队列以合并更改以优化和缩短更改数量是有意义的,例如,如果通过第一个增量命令添加节点,但是后续命令将其删除,则可以减少更改。
分析增量命令队列以合并更改来优化和缩短更改数量是明智的,例如,如果后续命令中将删除前面命令添加的节点,为什么要通过第一批增量命令添加这些节点呢。
分析增量命令队列以合并更改,从而优化和缩短更改数量,这个做法是有意义的。例如,如果前一个命令添加的节点会被后一个命令删除,为什么还要添加这些节点呢。
将增量命令集成到运行时的额外 “编辑阶段” 中:
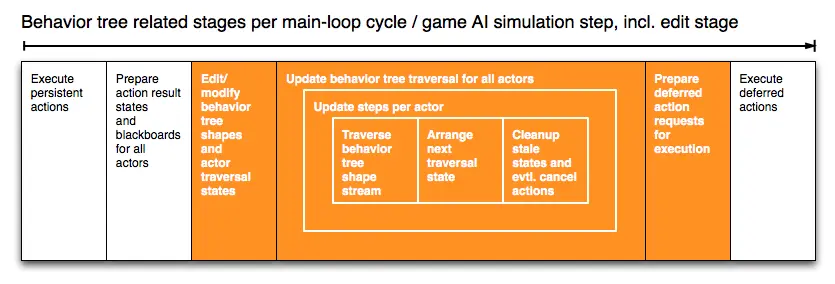
在后续的博文中,我们将探讨关于模块化、行为查找节点,以及如何应用 Actor 的运行时变更,编辑阶段也会发挥重要作用。
为了调试和监控运行时行为,开发时组件从指定的 Actor 和行为形状流接收数据。开发方面要能够发现游戏运行时、其行为流以及相关的 Actor 状态。需要运行时扩展来收集完整的遍历路径。需要从形状标记索引映射到编辑组件节点,从而进行可视化,设想树中更新的节点的高亮显示就像一种闪耀的“圣诞树”。除此之外,结合运行时流断点来单步执行 Actor 或所有 Actor 的遍历,这样也有助于调试。
在行为树开发期间,树遍历的速度或效率似乎没那么重要。在 GUI 中,每次只操作一个行为树方案,而不是遍历多个树和每个树中的众多 Actor。或许调试和监控运行时需要在编辑组件中进行高效的可视化,但在确定之前,我们将针对不同类型的节点去实现基于指针的方式,因为它最接近开发期间对行为层次结构中的父子关系的关注。
增量命令顺序和命令本身将定义运行时编辑阶段组件。
受 Insomniac Games 的 Chris Edwards 的启发6(由Nick Porcino建议),作者计划创建一个基于浏览器的 GUI ,它连接到游戏中的行为树运行时或游戏数据库。但这需要相当长的时间,作者无法将太多时间投入到整个行为树项目中。
尾声
在运行时,我们计划让行为树由行为流构成,这个数据流由行为树遍历和行为结果缓冲区以及世界知识黑板的 Actor 共享。利用这些流和缓冲区,更新内核每次更新一个 Actor(若在不同 Actor 上并行运行多个内核或行为树解释器,可以实现并行决策)。
线性和可预测的内存访问模式优先于随机内存访问,并且可能为预取打开大门,从而隐藏内存延迟。数据组织紧凑以适应本地存储或缓存,并节省内存带宽。索引数组元素简化了数据从一个内存地址空间到另一个的移动,例如从 Cell 的 PPU 到 SPU,或从 OpenCL 或 CUDA 中的主机内存到设备内存。行为树节点类型的数量是已知且有限的,其性能和内存占用不会浪费在多态、虚函数表等引入的不必要的可扩展性和间接性上。行为树运行时系统指导用户正确使用内存,它鼓励开发者考虑成块连续的数据,而不是陷入一堆指针之中。
延迟动作的执行,以及限定只有即时动作能访问 Actor 的黑板,也可以应用于面向对象的行为树设计,如果性能分析指出缓存未命中问题,它们也可能是重构的有益步骤。
行为树编辑的过程主要关注创建和通过快速迭代来调整模型。变更命令流连接着编辑组件和行为树运行时,从而实现即时变更和监控 Actor 的决策过程。
结果:面向数据的运行时行为流催生了开发时的行为树。
根据令人垂涎的 2011 年巴黎射击游戏研讨会7的摘要8,面向数据的行为树是今年许多游戏工作室的一个大题目。Angry Ant(Emil Johansen) 9的 Unity3D 行为树项目 Behave10,以及 Joacim Jacobsson11 的开源 calltree12 项目甚至比运行时解释行为流更进一步,它们将基于图形或语言的行为树描述编译成一个更高效的运行时格式。
根据令人垂涎的 calltree 项目,我们甚至可以比在运行时“只”解释行为流更进一步,而是将基于图形或语言的行为树描述编译成一个更高效的运行时格式。
总而言之,行为树通过流式处理和数据导向设计获得了开发便利性与运行效率。但仍有许多问题有待探索,需要持续试验来发现最佳实践。
问题
因为还没有一个真正的游戏来设计行为树,因此还有一些好奇的问题:
- 如今内存有宝贵?对于当今的游戏主机来说,使用带有守卫标记的纯流方法(使行为流大小加倍)是否会占用过多内存?
- 接着上个问题:你的行为树有多少节点,每个关卡使用多少行为树,有多少 Actor 共享同一棵树?
- 是否要设计一种方式来显式取消正在运行的动作?还是说,如何每个执行动作的系统在每个模拟tick中隐式取消未请求的动作,是否这样就足够了?取消动作应该通过显式的行为树节点来处理吗?
- 支持延迟动作和持续动作有意义吗?或是仅仅延迟动作就足够了?
- 应该允许 Actor 通过更改黑板来影响遍历吗?或者它们只应在遍历期间读取黑板而不是写入黑板?是否需要分离 Actor 黑板的只读部分和读写部分?
- 从树结构转向有向无环图(DAG),并允许共享整个子树。这么做是否有意义?如果是这样,每个到共享子树的路径应该有自己的遍历和结果状态缓冲区,还是遍历状态和行为结果状态也应该共享?这将打破对流的始终正向迭代,循环节点也是如此。
计划
接下来的文章可能会稍微偏离行为树主题,例如深入探讨并行编程,继续记录双重行为树的设计(运行时和编辑时)的测试驱动实现。我非常好奇所有理论上的优势(例如更高效的内存访问)是否能实现,以此来证明其实现复杂性较之朴素的面向对象解决方案是合理的。为了可视化的行为树编辑器,进入Web开发的世界也是我渴望探索的东西——有更多新技术可以学习和实验。
非常感谢您的时间!期待您的反馈、批评和问题,也很想听听你在神秘的行为树森林中的探险!
参考资料
-
1.2CPU和GPU的设计区别 - Magnum Programm Life - 博客园 (cnblogs.com) ↩︎
-
Niklas 离开 Bitsquid 之后,开始了新引擎 The Marchinery 的开发工作,并写了很多关于 Data-Oriented-Design 相关的文章。参考 The Story behind The Truth: Designing a Data Model ↩︎
-
Niklas Frykholm, Managing Decoupling Part 3 - C++ Duck Typing ↩︎
-
为每个 Actor 维护一个世界知识黑板,通过即时动作来更新黑板,使实现条件变得更加容易,因为即时动作只能访问对应 Actor 的黑板。 ↩︎
-
巴黎射击游戏研讨会(Paris Shooter Symposium)是一个由 Game/AI Conference 组织的研讨会,专门致力于第一人称和第三人称射击游戏以及战斗游戏。 ↩︎
-
Paris Shooter Symposium 2011 | Game/AI Conference™ (archive.org) ↩︎
-
calltree: A slim Behaviour Tree implementation. (github.com) ↩︎