《巨兽战争(Gigantic)》的游戏AI行为树设计
偶然看到 Managing AI in Gigantic 和 Advanced Behavior Tree Structures 这两篇文章,简述了一款 PvPvE 游戏 Gigantic 的 AI 架构,提供了一些不一样的思路。
背景

Gigantic是一个结合了PVE的5v5的多人对战游戏。对战双方各有一个叫做守护者的NPC巨兽。玩家通过在己方泉水召唤生物,定时收集泉水,通过击杀敌方英雄或泉水召唤物来为己方巨兽充能。双方围绕保护己方巨兽,攻击敌方巨兽来展开对抗,直到消灭对方巨兽,赢得胜利。
作为一款快节奏的PvPvE游戏,NPC守护者是游戏的关键要素,其AI的表现至关重要。
有限状态机不够灵活,重用节点不方便。使用行为树可以解决这一问题,而且可以轻松地同 Utility AI,GOAP 等其它方案结合。
实现
一般执行逻辑
关于行为树的基本介绍以及工作原理,不予赘述。参看 AI行为树的工作原理
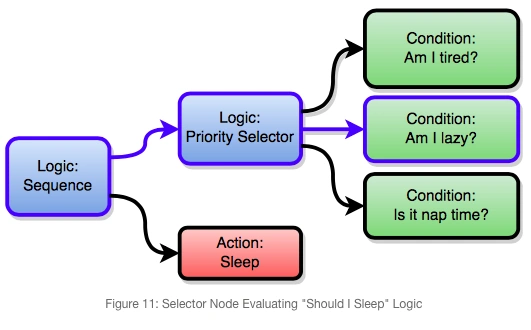 一般来说,行为树的执行顺序采用深度优先,父节点根据子节点执行并返回的状态作为输入,执行自身节点的逻辑,并返回其处理结果。
一般来说,行为树的执行顺序采用深度优先,父节点根据子节点执行并返回的状态作为输入,执行自身节点的逻辑,并返回其处理结果。
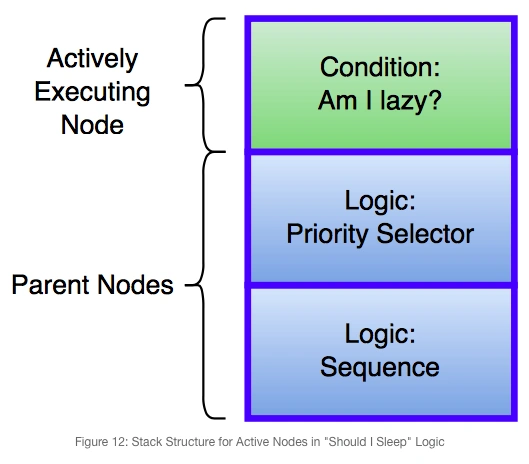
在子节点返回成功/失败状态之前,行为树会从子节点继续执行,直到其返回成功/失败。然后执行其父节点,直到行为树根节点返回成功/失败。因此 Gigantic 采用栈来实现行为树的执行逻辑。子节点返回结果后从栈顶弹出,继续执行栈顶的节点。若该节点为Select,Sequence之类的复合节点,需要继续处理剩余的子节点,则将子节点压入栈继续执行。
使用栈来实现,有以下几个优点:
- 栈中只包含当前执行的路径,易于调试;
- 使用享元模式可实现树结构的共享,与 Agent 关联的行为树任务实例分离,占用内存更少。
- 实现轮询更简单:有些特殊的节点会在子节点每次执行前,自身也会执行。从而来实现任务及时中断退出,一般叫监测节点。如果有这种功能的节点,那么需要从栈底部向上依次执行该节点。(个人觉得这个理由有些牵强,不符合栈的使用场景,若使用C++标准库的栈则无法实现这个需求。)
注:作者没有指出这种实现的缺点,但需要注意的是:行为树每次执行时伴随着频繁的入栈出栈操作,如果处理不当可能造成大量的内存碎片。
并行处理
动作游戏里NPC经常会同时执行多个动作,比如一边移动一边攻击,其行为树如下图所示:
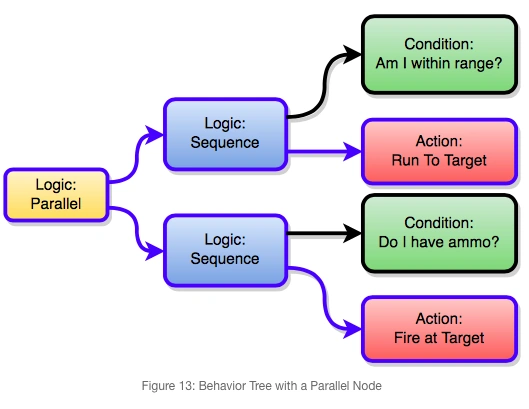
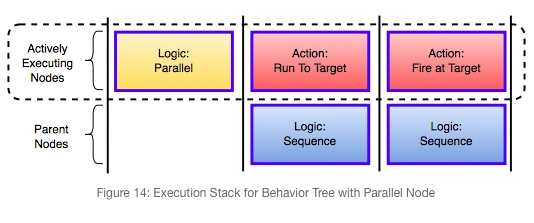
针对这个需求,一般行为树都会提供并行节点(Parallel)。Gigantic 也使用栈来实现并行节点。为并行节点的每个分支创建新栈。并行节点执行时会依次切换至其分支对应的栈,从而实现并行处理,类似于有些语言的协程(Coroutine)。
注:这个方法可以扩展成真正的并发实现。线程足够的情况下,让每个分支执行在不同的线程上。
难点
事件处理
为了维持行为树的执行和便于理解,Gigantic 将事件处理和行为树分离,事件的响应结果作为状态保存,便于行为树轮询时查询。
注:将状态与决策分离,可以更好地实现组件的模块化,不仅行为树,其它如GOAP,HTN为主要框架的架构也可以这样处理。
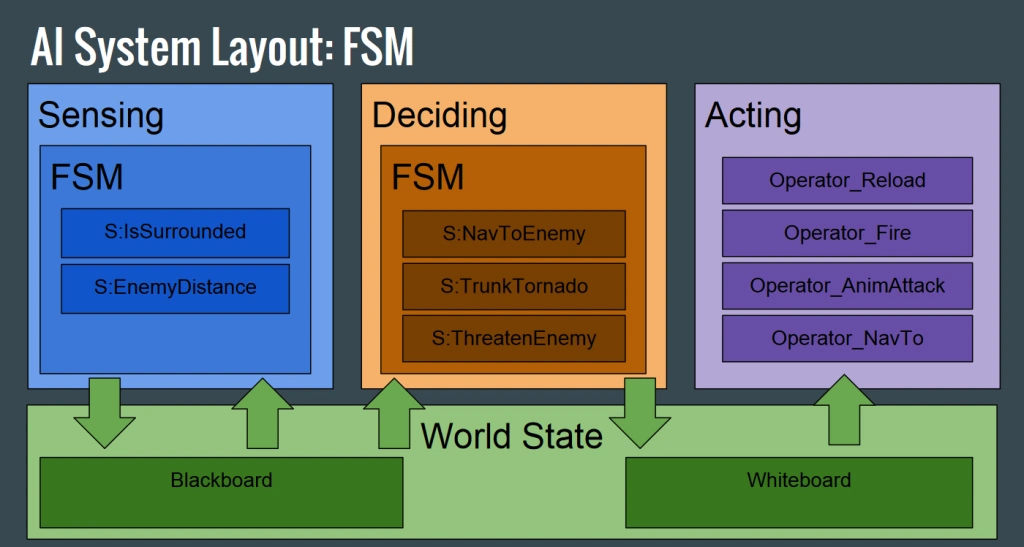
具体可参考 Humphreys. 2016. Modular AI System
重用
随着游戏中 AI 的行为逐步丰富,行为树的复杂度也随之上升。如果树节点不具备重用的特性,那么不论是编写 AI 逻辑,还是调试功能都会带来很多不便。
因此 Gigantic 引入“子树”这一概念。在主树中加入“Subtree Proxy”类型的节点,并设置指定的子树,执行时就会跳转到对应的子树。子树的结构也采用栈,因为它本质上也是一棵行为树。需要注意的是,要避免子树滥用造成的循环。如果有必要,在编辑行为树时加入循环检查,提醒设计师注意这一问题。
注:子树不是新鲜概念了,但循环检测还是有必要的,即使有时是刻意为之。
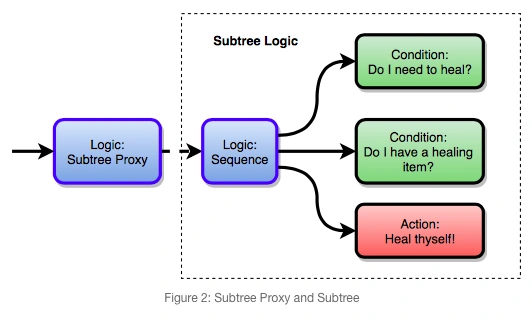
优化
通常 AI 代理的行为都是类似的,很多NPC共用同一个行为树。因此利用享元模式,可以将行为树的结构与代理的状态数据分开。行为树的结构数据应当是不互斥的,静态且无状态的。即使代理的数量激增,其所占用的行为树的静态数据也始终保持不变。
除此之外,还可以使用面向数据的引擎设计来组织数据。我们知道行为树是按照深度优先顺序来执行的,所以我们可以按深度优先顺序来扁平化行为树的结构及其状态数据。这样在执行时可以按数组的顺序连续访问数据,较少的状态数据加上合适的内存对齐,我们就可以拥有一个缓存友好的行为树系统。但注意,魔鬼存在于细节之中!(其实没那么容易)
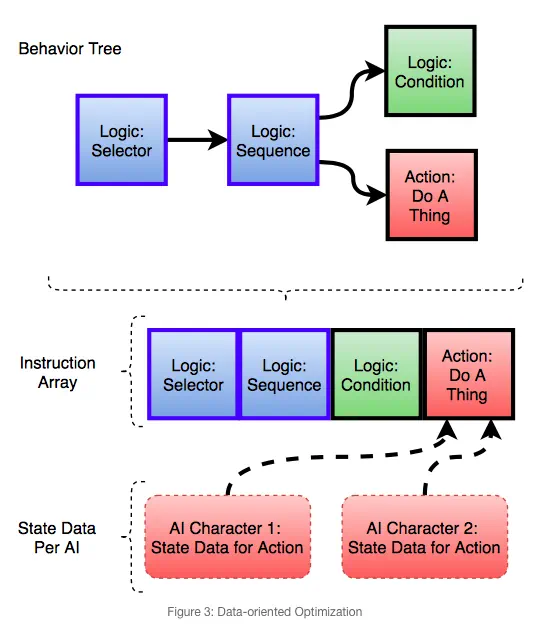
注:关于“Data-Oriented Design”,可以参考 CppCon 2014 时 Mike Acton 的演讲 《“Data-Oriented Design and C++"》。
- Video: CppCon 2014: Mike Acton “Data-Oriented Design and C++” - YouTube
- Video: Mike Acton: Data-Oriented Design and C++ - 哔哩哔哩_bilibili
- Slides: CppCon2014/Data-Oriented Design and C++ - Mike Acton - CppCon 2014.pptx
这种将有状态数据和无状态数据的拆分,带来的另外一个效率提升是:可以对无状态数据,即行为树的实际结构和执行逻辑,进行简单的多线程无锁访问。据此我们就可以在应用古斯塔夫森定律时,最大化地并行执行行为树。无状态数据是隐式只读的,且可以有多个无竞争关系的读取器。需要写入的部分则是有状态数据,且存储在内存的不同位置,因此不会引起竞争条件。
参考资料
- Managing AI in Gigantic | by Gautam Vasudevan | Medium
- Advanced Behavior Tree Structures | by Gautam Vasudevan | Medium
- Humphreys. 2016. Modular AI System
- CppCon 2014: Mike Acton “Data-Oriented Design and C++” - YouTube
- What is Data-Oriented Game Engine Design? (tutsplus.com)
- 如何评估并行程序的性能 — python-parallel-programming-cookbook-cn 1.0 文档 (python-parallel-programmning-cookbook.readthedocs.io)